
大家好,今天荣姐再给大家介绍一下 Ollama+FastGPT 部署本地deepseek大模型和搭建知识库的流程。
Ollama大家已经很熟悉了,本地部署非常方便,一条命令就搞定了。
那为什么选择FastGPT 呢?
可以看下部署后的界面,网页端访问,支持新建简易应用、工作流、插件、知识库等功能,无需编程就可以灵活自定义工作流。
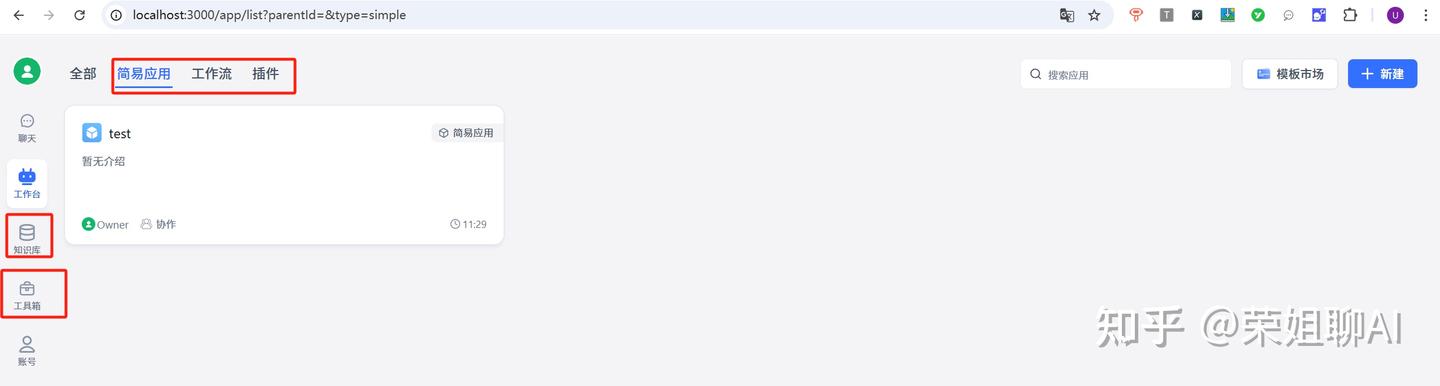
内置了比较丰富的模版和插件,支持联网搜索、飞书、钉钉、企业微信等插件,可以无缝衔接到工作软件中。
支持的模型种类较多,本地化部署或者国内外主流模型都支持。
最重要的是,FastGPT更侧重于构建知识库问答系统,强调对特定领域知识的理解和检索能力。它的目标用户主要是希望利用自有数据构建智能客服、知识助手等应用的开发者和企业。
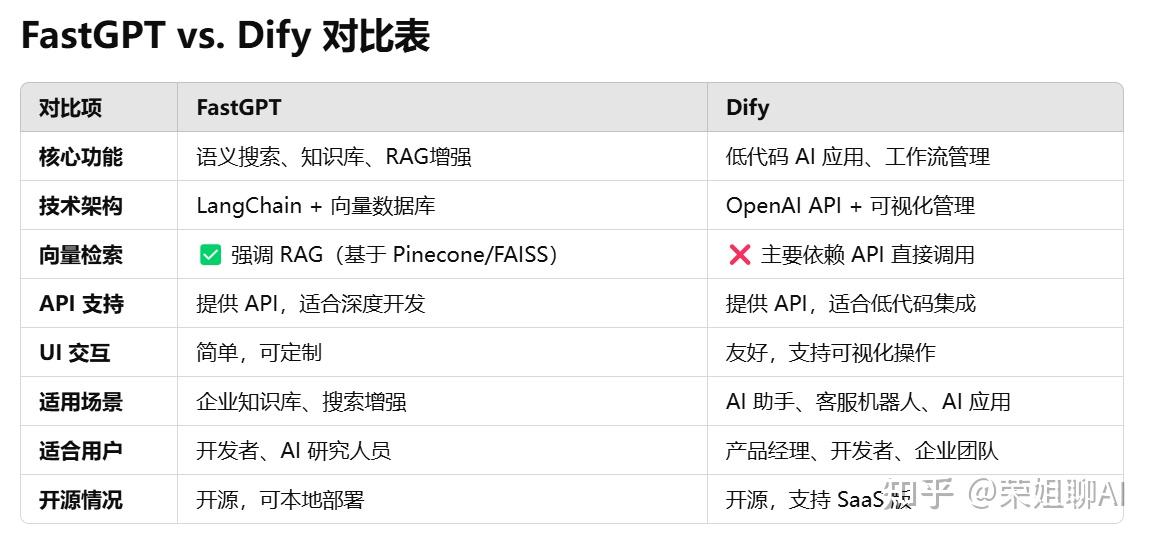
下面是 FastGPT 和 dify 的一个对比表,如果你想打造一个基于 RAG 的知识库 AI(如企业文档检索), 选择 FastGPT 更合适。
1 Ollama本地化部署
Ollama 是一个用于本地运行大语言模型(LLMs)的开源工具,提供简单的界面和优化的推理引擎,使用户能够在个人设备上高效地加载、管理和运行 AI 模型,而无需依赖云端。
官网地址:https://ollama.com/
1.1 下载Ollama
下载地址:https://ollama.com/download
找到与你本地操作系统匹配的版本,本文以windows系统为例。下载以后默认安装即可。
1.1 部署DeepSeek R1
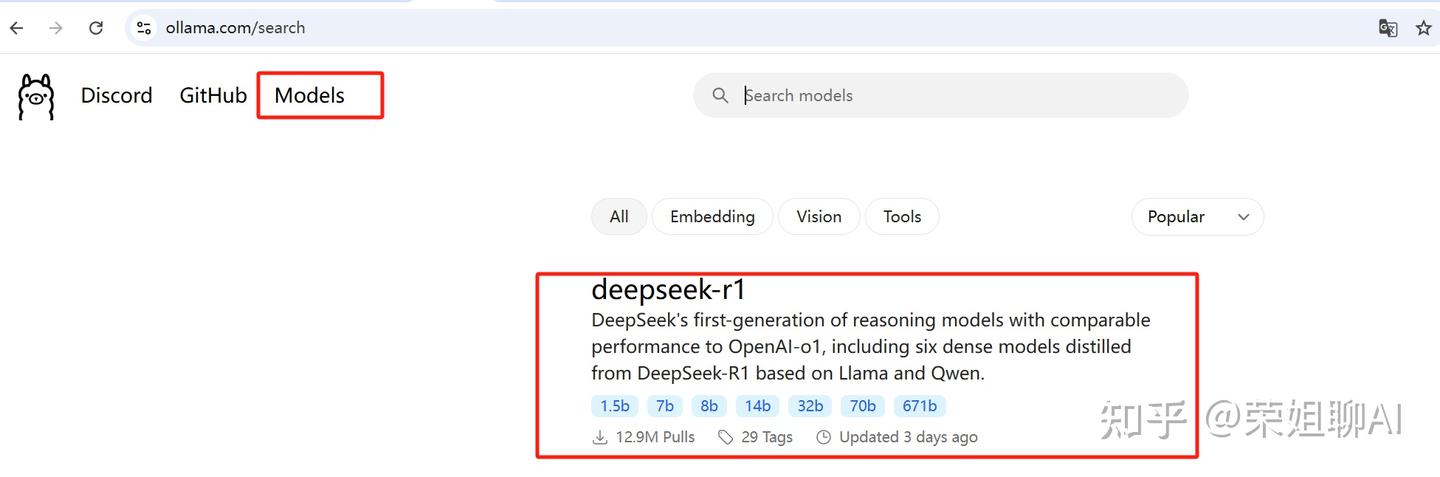
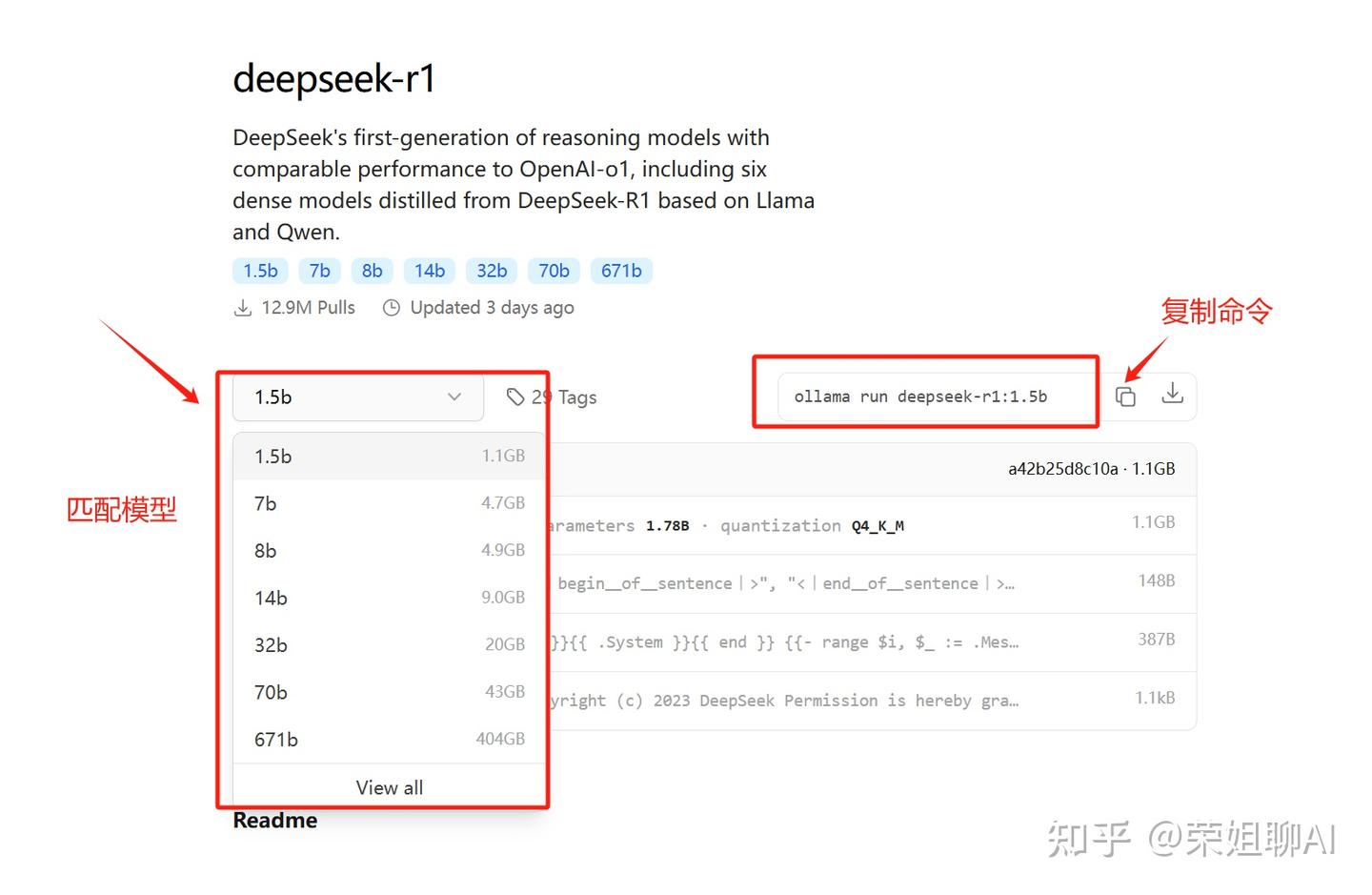
1、在Ollama官网点击Models,找到deepseek-r1,点击进去。
2、选择你想要安装的模型,复制命令。我是演示流程,选择deepseek-r1:1.5b。大家要根据自己实际需求来匹配。
Ollama运行命令为:ollama run deepseek-r1:1.5b
3、在终端运行命令:ollama run deepseek-r1:1.5b。运行的命令根据你选择的模型进行匹配。
看到success就成功了。可以输入你是谁来测试一下。

1.2 部署Embedding
1、找到嵌入模型,我这里选个小一点的:nomic-embed-text。大家根据自己需求来。这是后续搭建知识库要用到的。
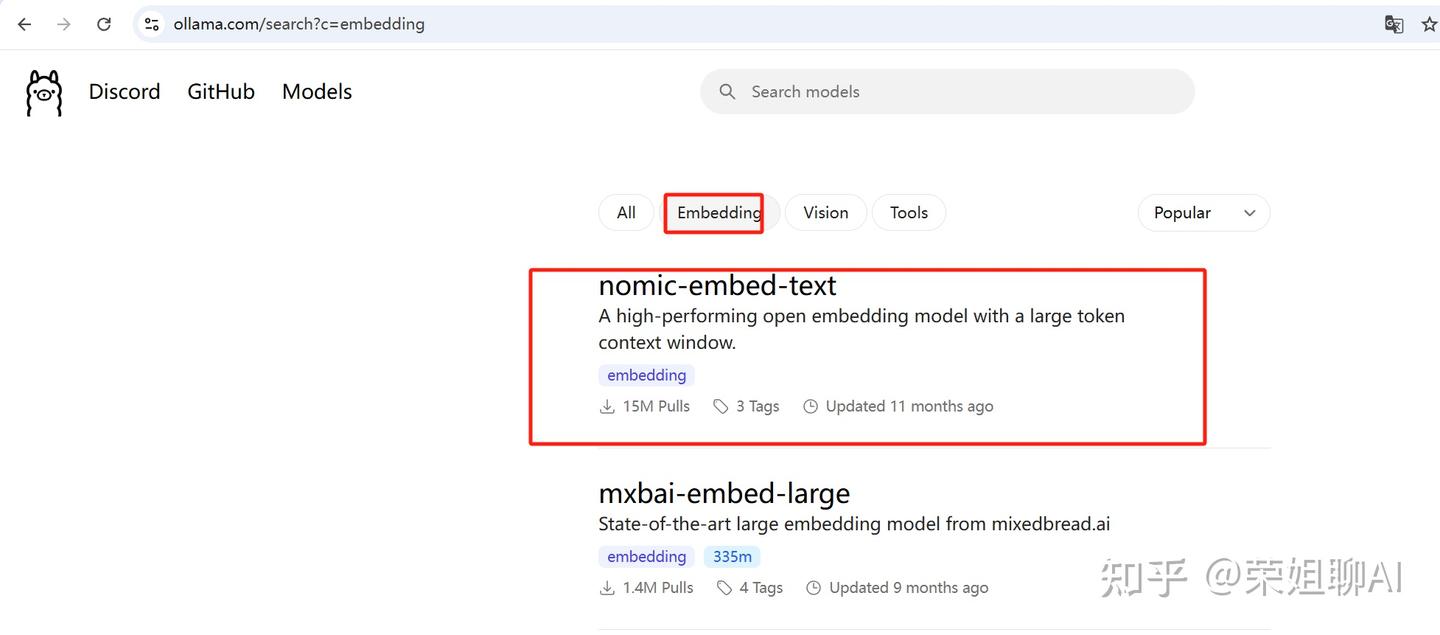
2、选择版本,复制命令。荣姐就用最新的了。
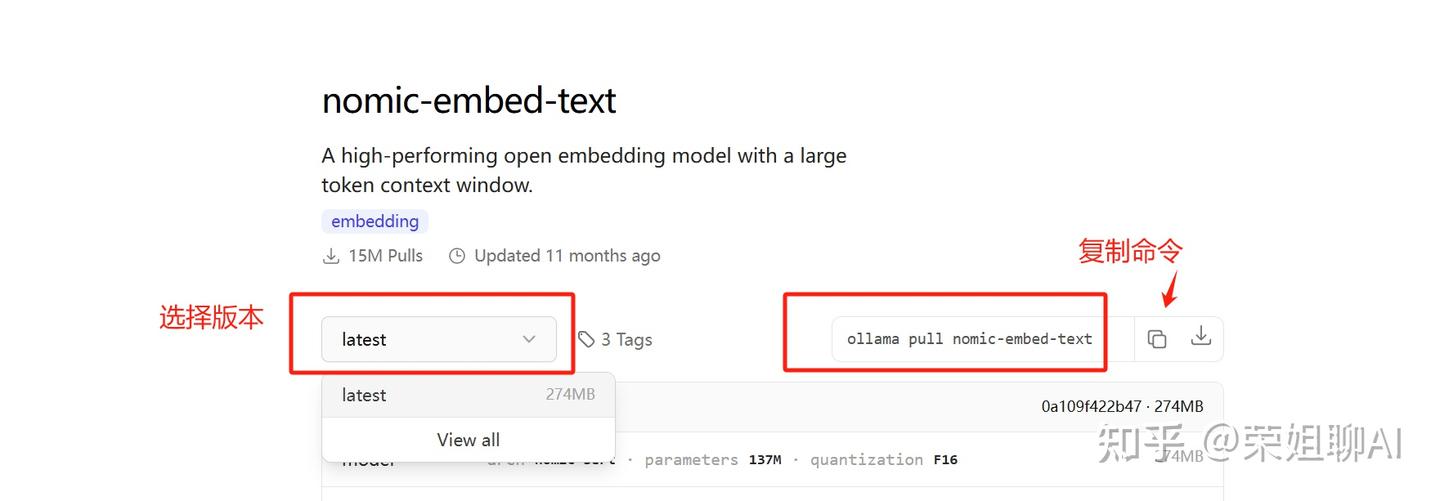
3、在终端运行命令:ollama pull nomic-embed-text
看到success就成功了。

1.3 检查部署是否成功
输入 ollama list 检查是否部署成功。我这里为了测试安装了两个嵌入模型。

2 安装Docker
Docker 是一个开源的容器化平台,用于开发、交付和运行应用,使应用及其依赖能够以轻量级、可移植的方式打包并运行在任何环境中。
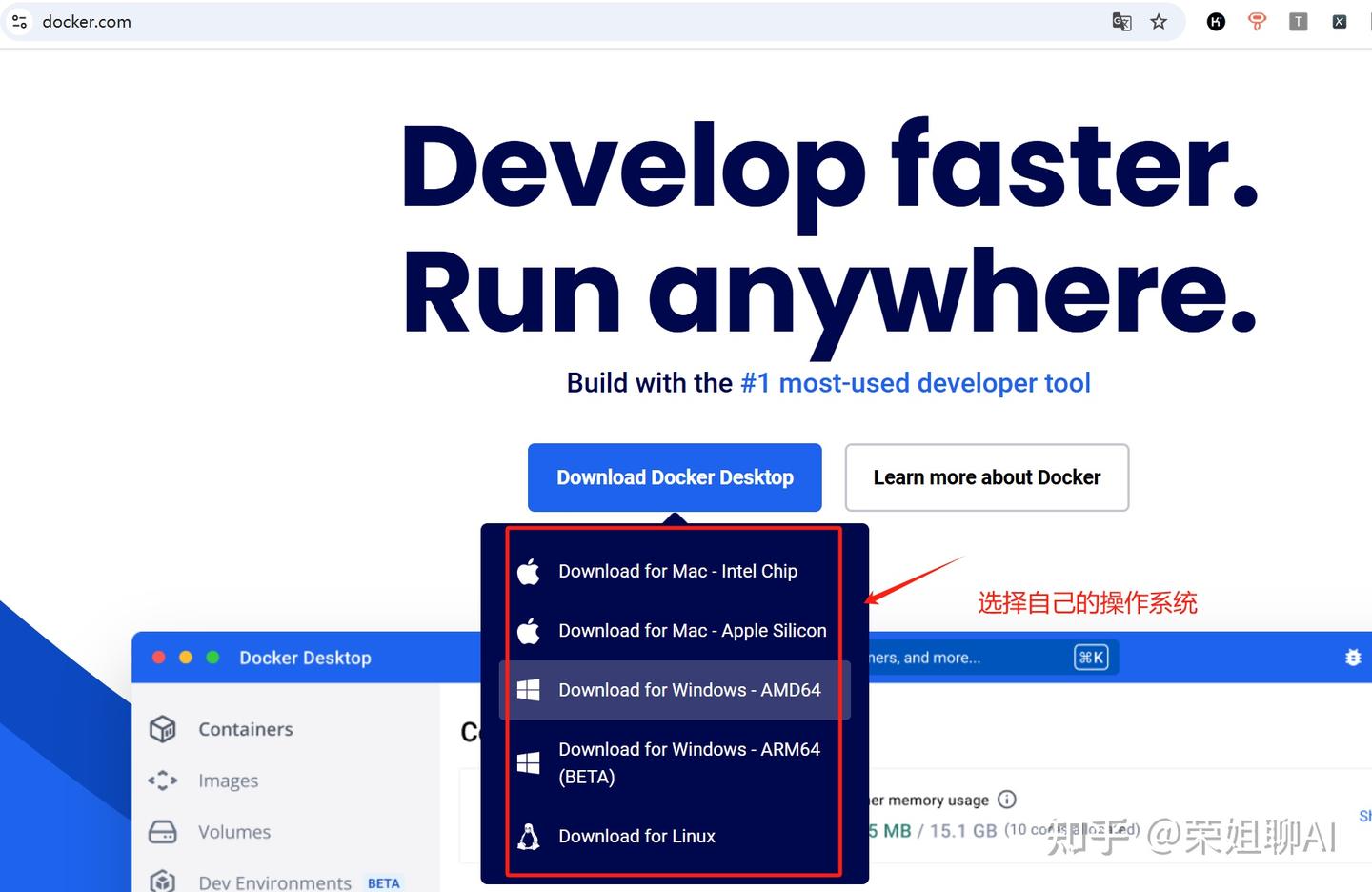
点击下载,选择自己的操作系统进行下载。荣姐还是用windows系统来测试。
安装过程非常简单,不懂docker的小伙伴不用担心,一路傻瓜式操作即可。
下载完成后一路默认安装。安装完成后需要登录。
登录后进入桌面docker界面。看到这个界面代表安装成功。
3 部署FastGPT
官方手册:https://doc.tryfastgpt.ai/docs/development/docker/
荣姐本次介绍使用Docker Compose 快速部署。还是使用windows环境。
3.1 安装FastGPT
3.1.1 下载安装Ubuntu
官方建议将源代码和其他数据绑定到 Linux 容器中时,将其存储在 Linux 文件系统中,而不是 Windows 文件系统中。所以我这里用windows商店里的Ubuntu来安装FastGPT 。
我是在windows电脑安装的,在Microsoft Store找到Ubuntu,下载并安装。
本例下载Ubuntu 22.04.5 LTS版本。
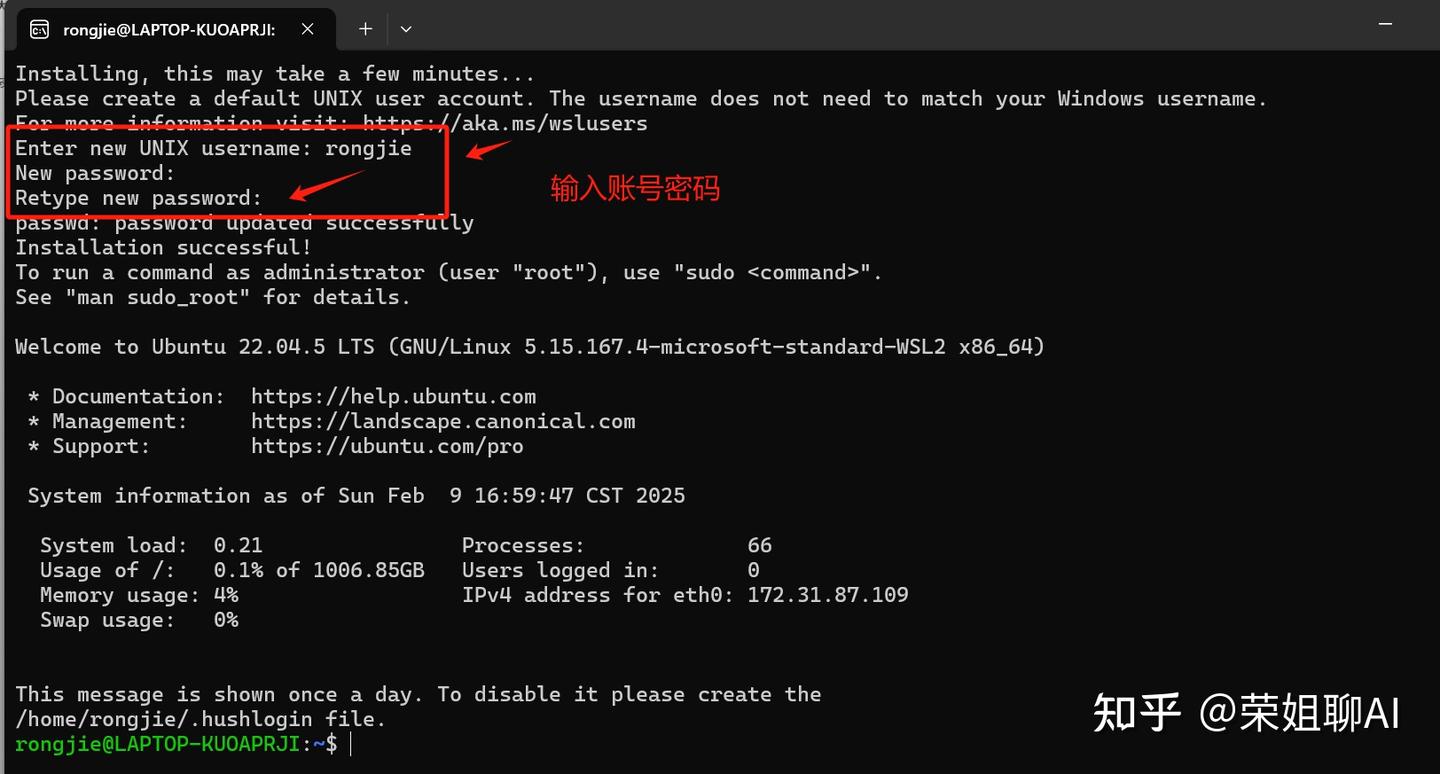
下载后打开进入安装界面,设置账号密码。我这里添加了账号为rongjie
3.1.2 创建 fastgpt 目录并下载配置文件
创建fastgpt目录,下载config.json文件和docker-compose.yml
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
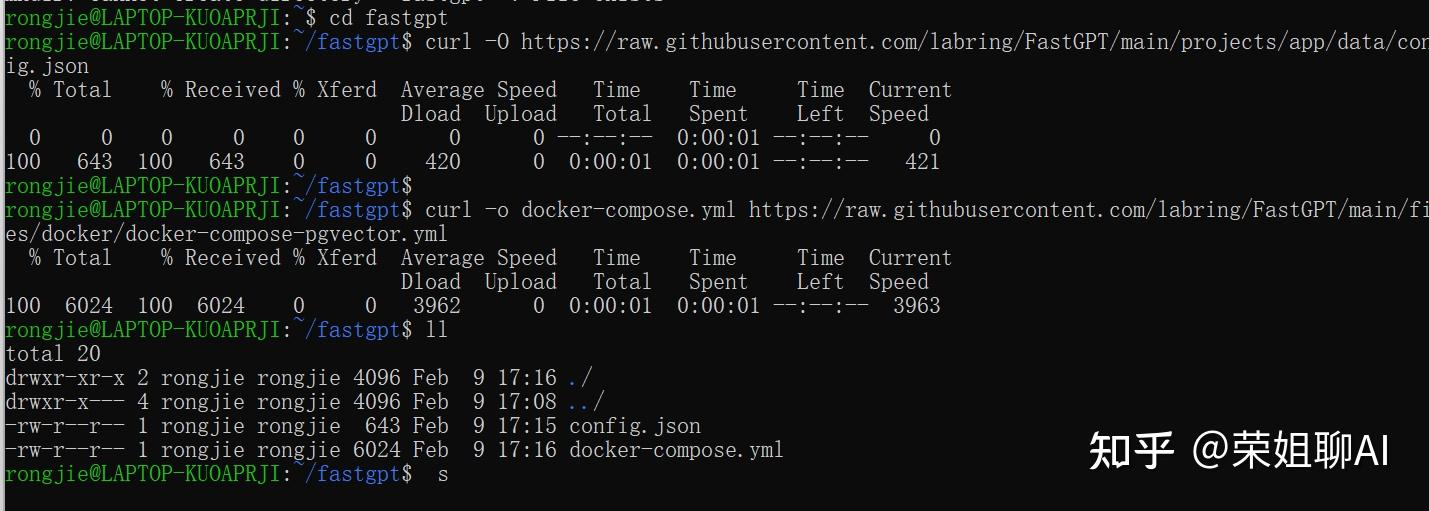
windows目录在此:\\wsl.localhost\Ubuntu-22.04\home\rongjie\fastgpt
可以在windows目录看到Linux中多了Ubuntu-22.04,找到我们新建的文件夹fastgpt。
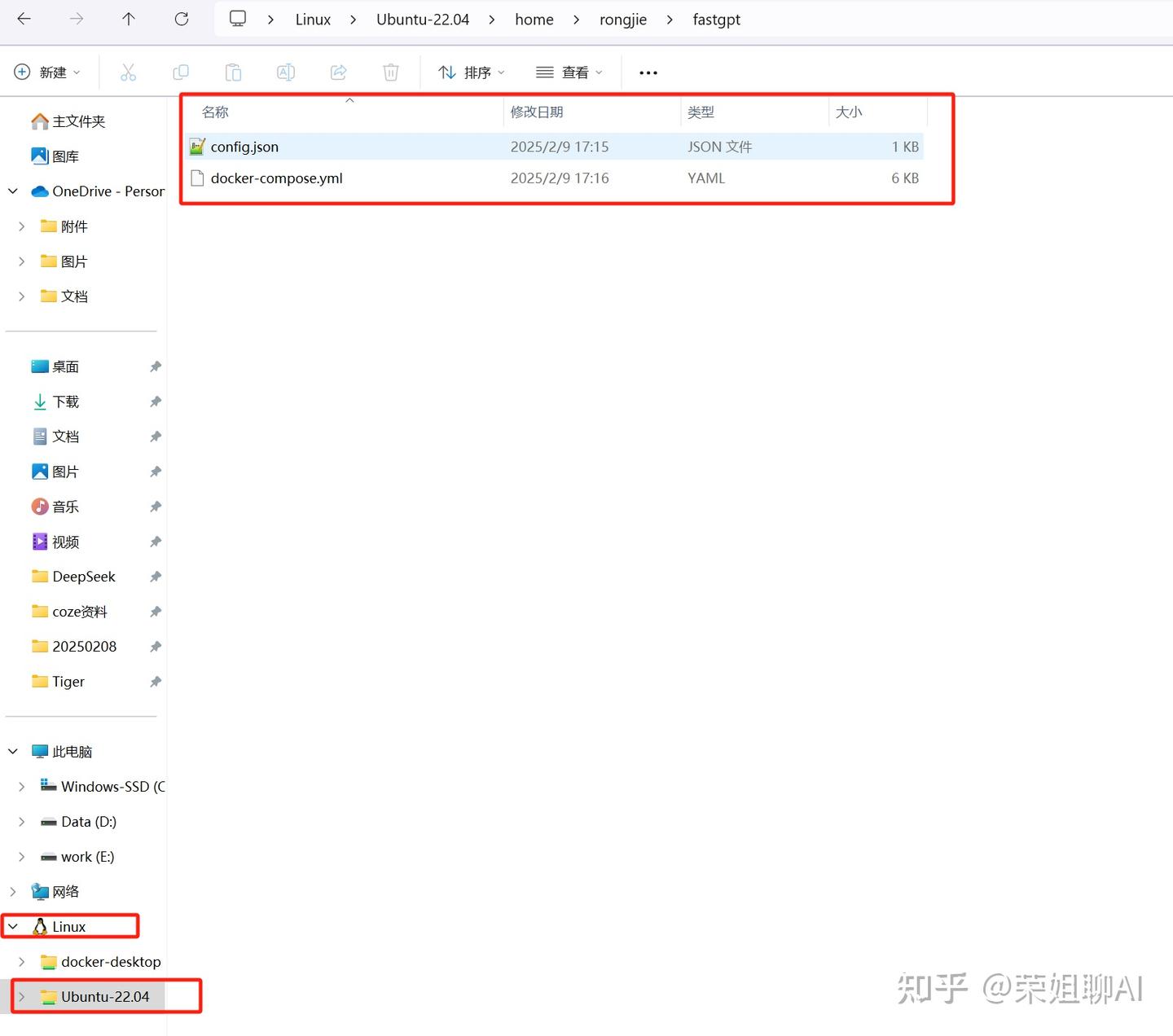
3.1.3 修改配置文件
修改配置文件:docker-compose.yml。
修改 FE_DOMAIN 和 OPENAI_BASE_URL 两个配置项如下:
# 前端访问地址: http://localhost:3000
- FE_DOMAIN=http://localhost:3000
# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
- OPENAI_BASE_URL=http://host.docker.internal:3001/v1
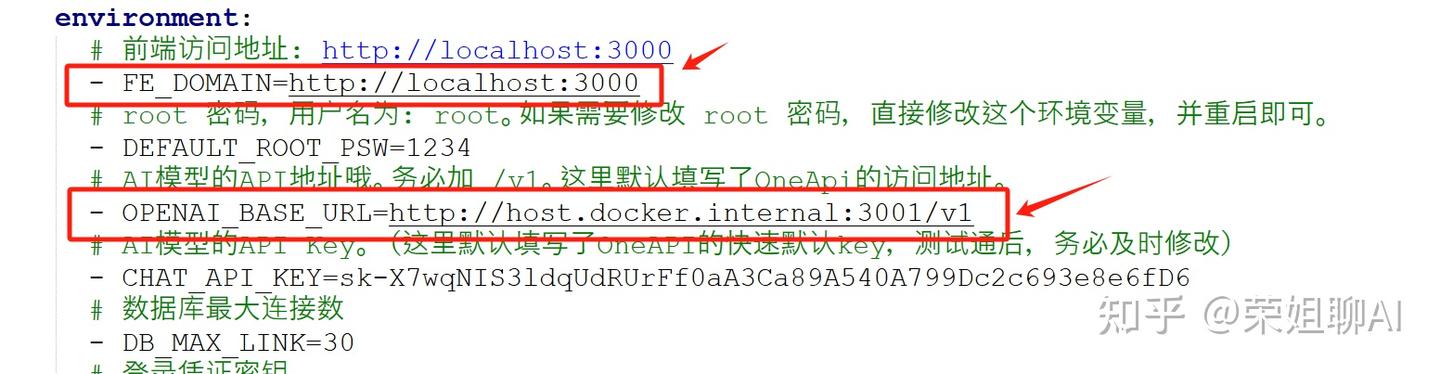
3.1.4 启动容器
在 ubuntu中 启动容器,命令为:docker-compose up -d
如果容器无法正常启动,可在桌面 docker 这里修改一下配置。
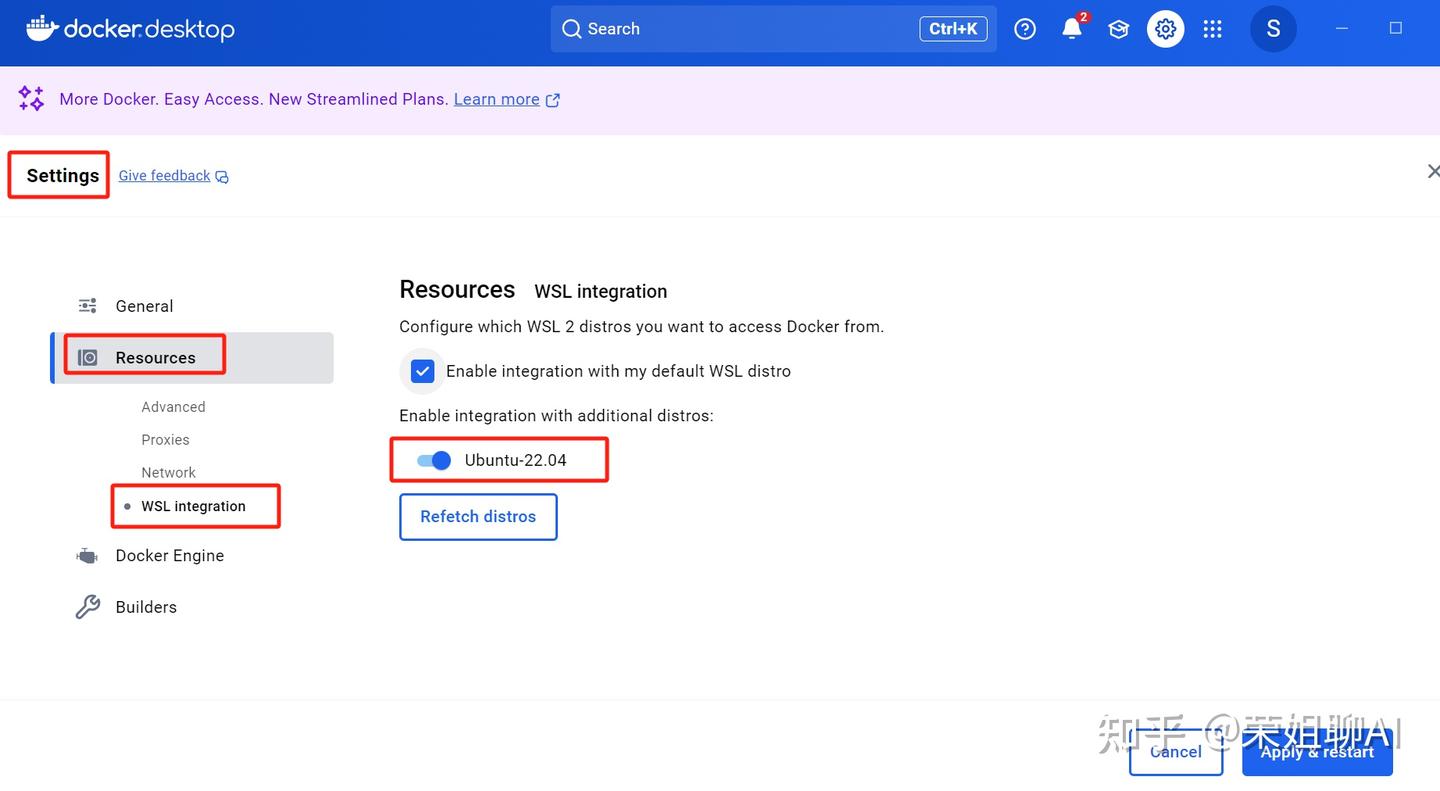
容器启动成功后会在 Docker 中看到fastgpt。
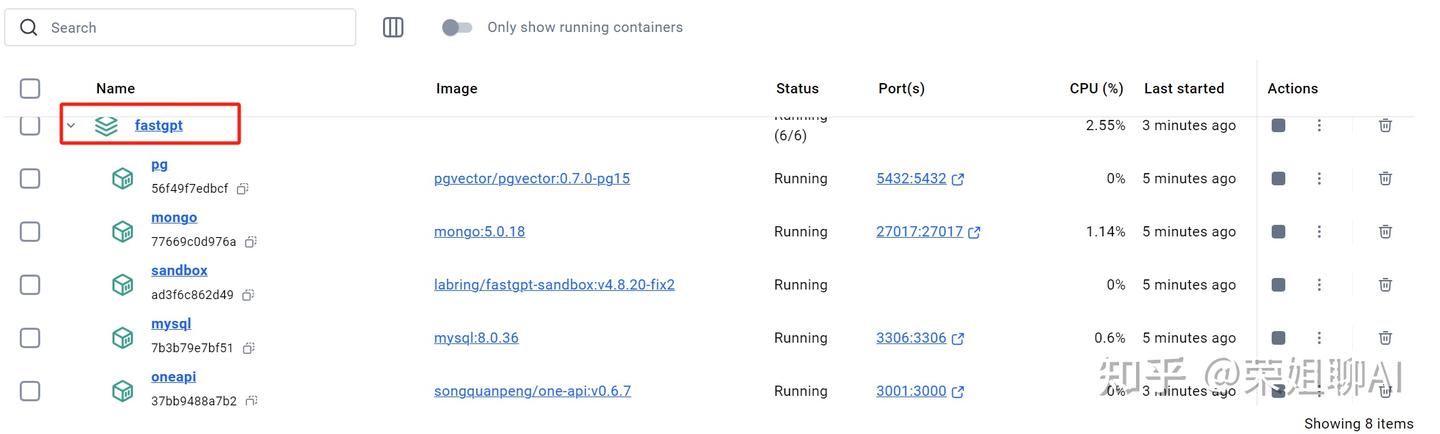
3.2 配置OneAPI
3.2.1 登录OneAPI
打开OneAPI地址:http://localhost:3001/
默认账号密码:root/123456
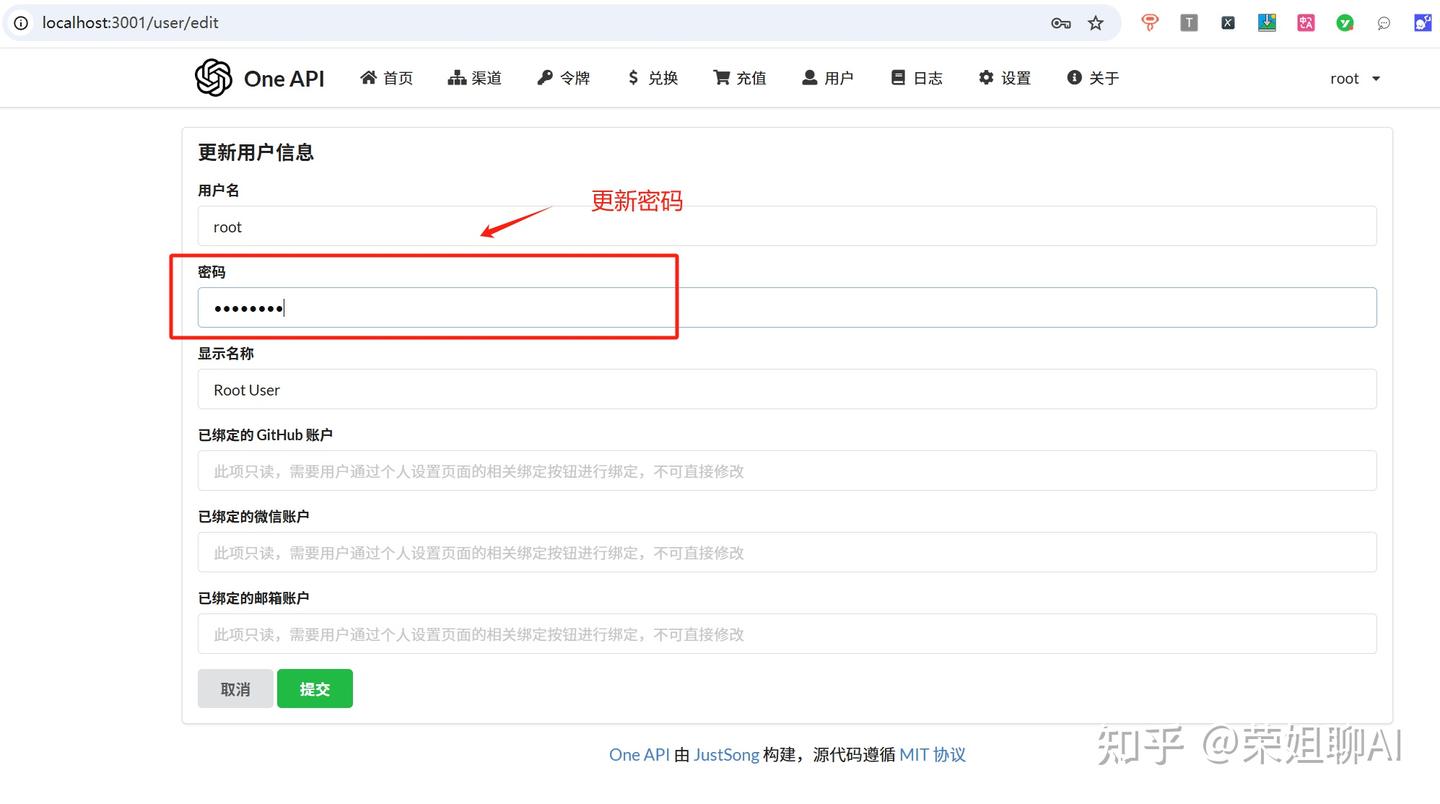
登录后先修改密码:
3.2.2 添加渠道
点击渠道,添加新的渠道。
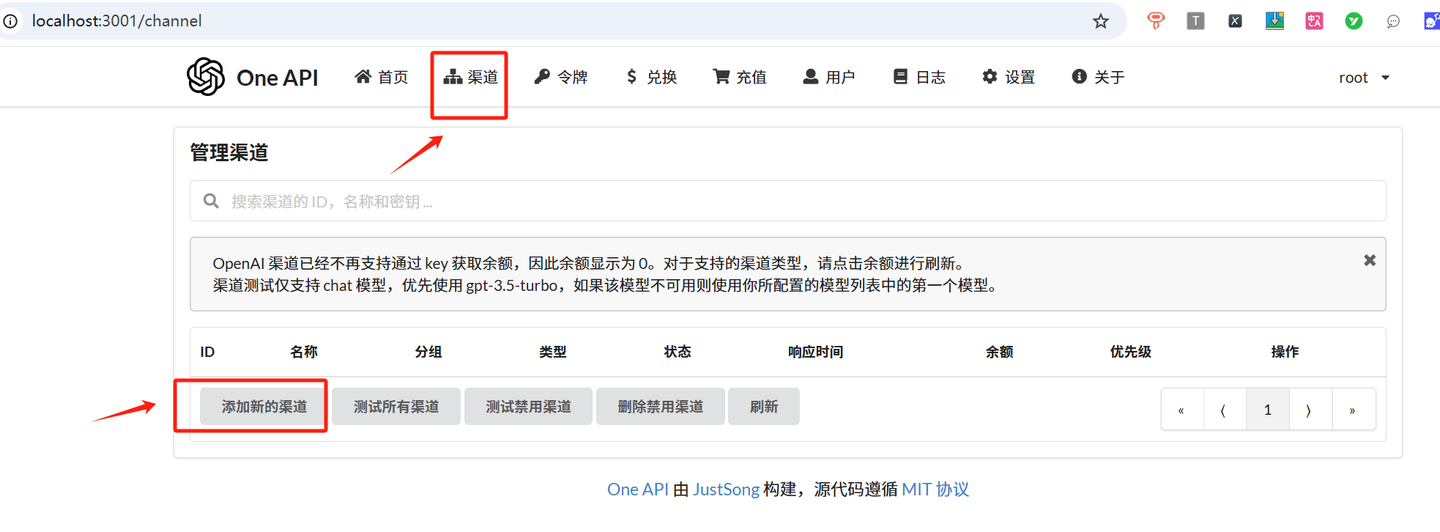
1、添加deepseek渠道。渠道类型选择Ollama,名称随便填,我这里就选择ollama:deepseek-r1:1.5b。
模型那里先清除所有模型,然后输入自定义模型deepseek-r1:1.5b,点击填入。
密钥随便填就行。
代理填写:http://host.docker.internal:11434
最后点击提交按钮。
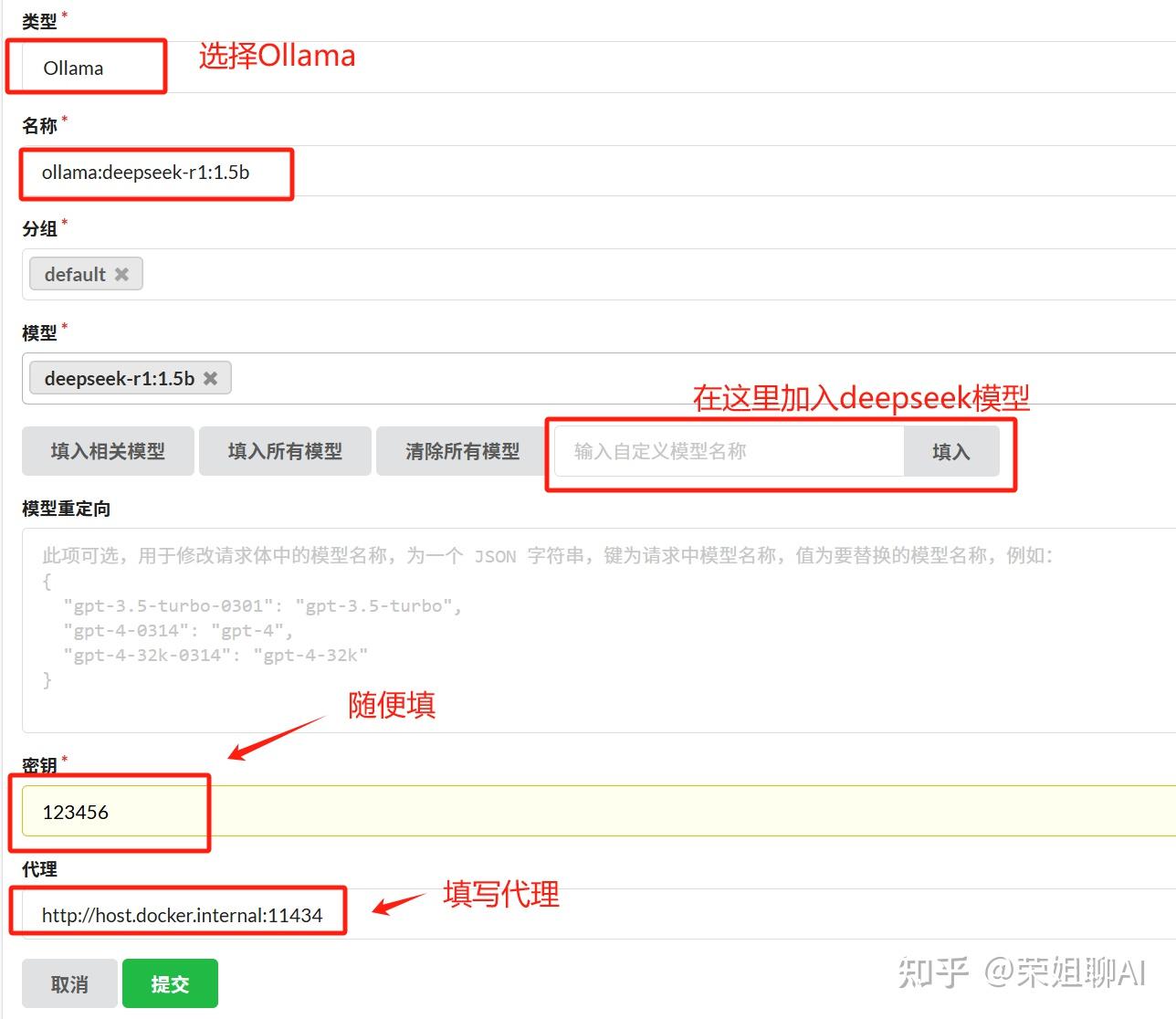
渠道添加完成需要测试,看到右上角测试成功即可。
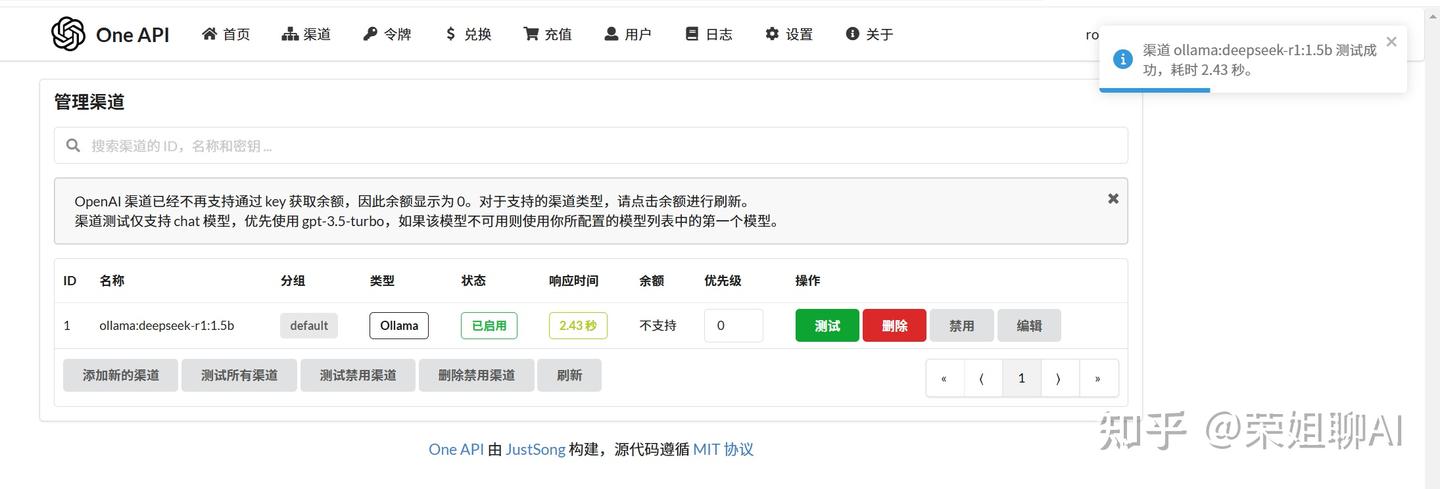
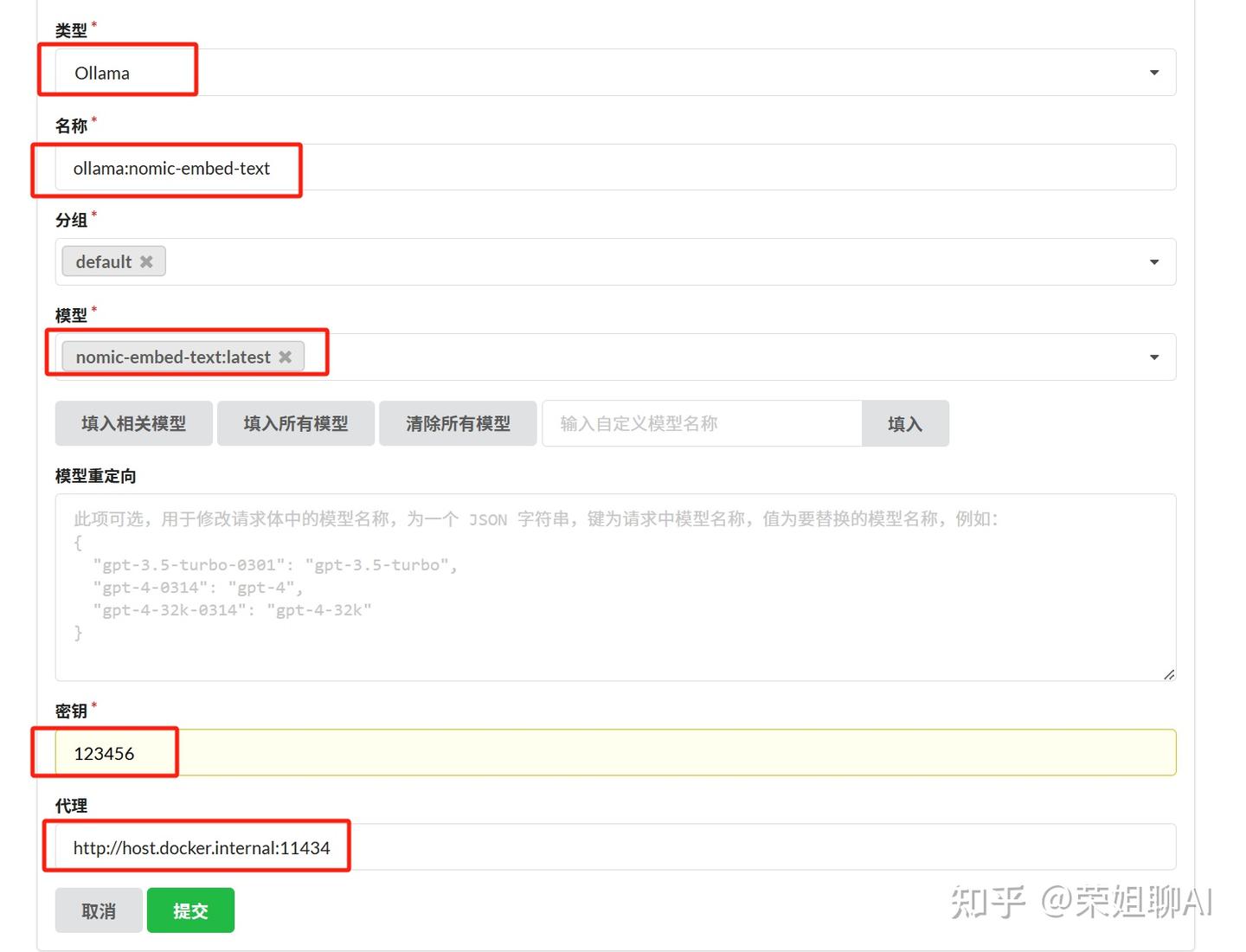
2、添加嵌入模型渠道:
类型选择Ollama,名称随意,我这里就填ollama:nomic-embed-text:latest。
模型那里还是先清除所有模型,然后输入nomic-embed-text:latest。
密钥随意,代理填写:http://host.docker.internal:11434
最后点击提交按钮。
3.2.3 添加令牌
点击令牌菜单->添加新的令牌。
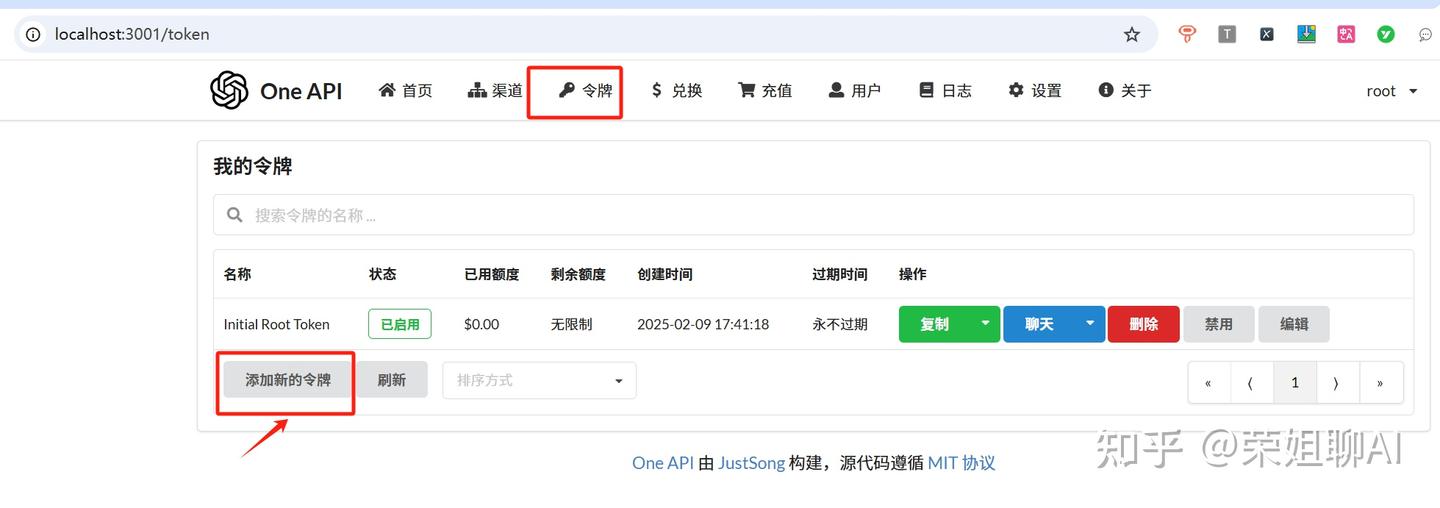
填写令牌名称,随意填写就行,模型要把之前的两个都选上,过期时间我就选选择永不过期,额度选择无限额度。
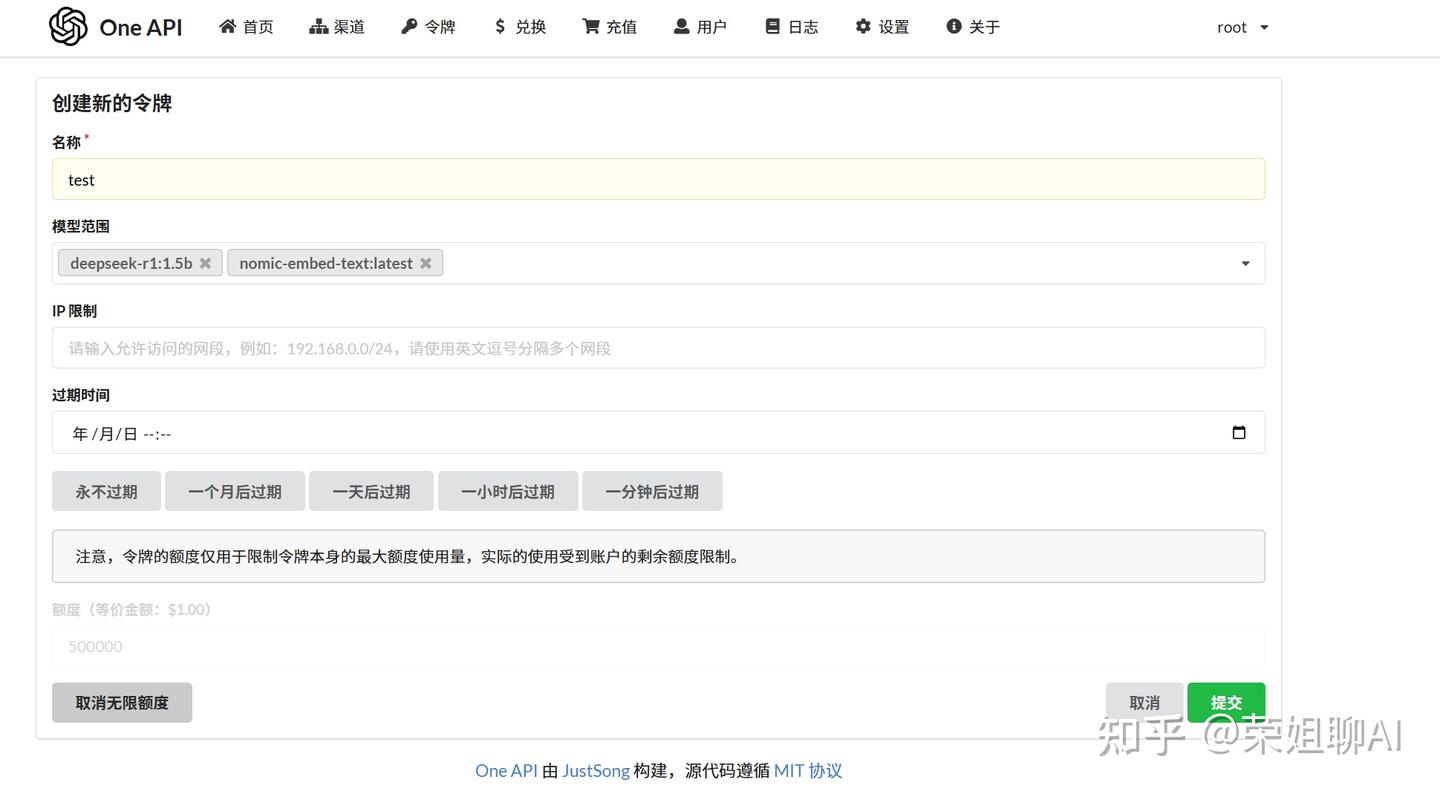
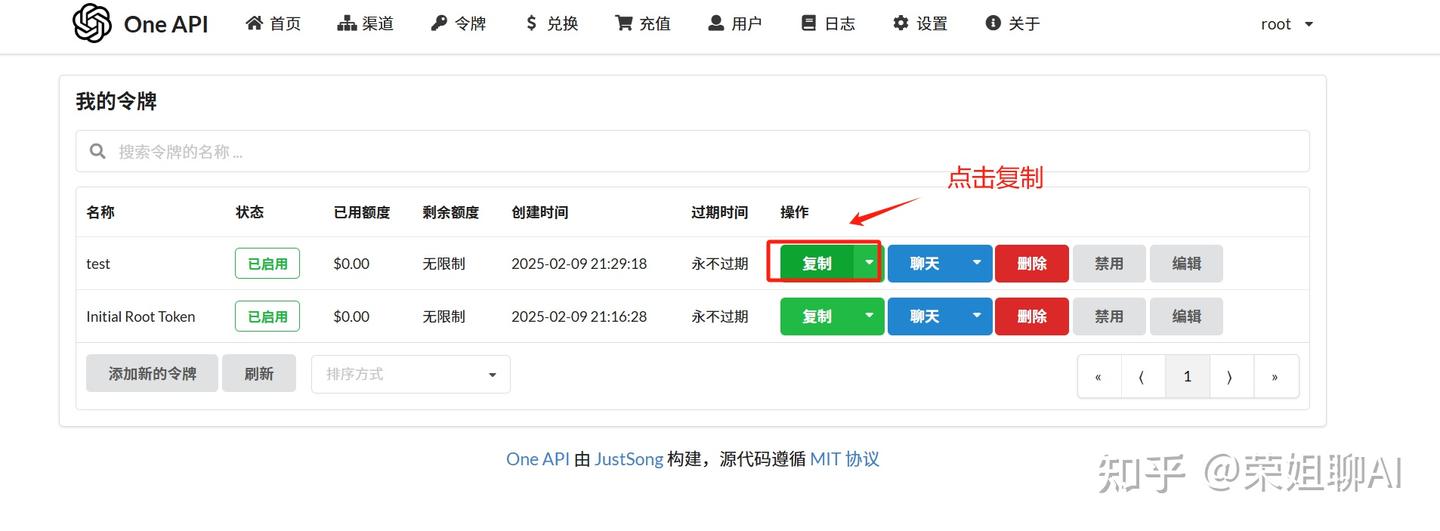
令牌添加好后,点击复制保存起来。
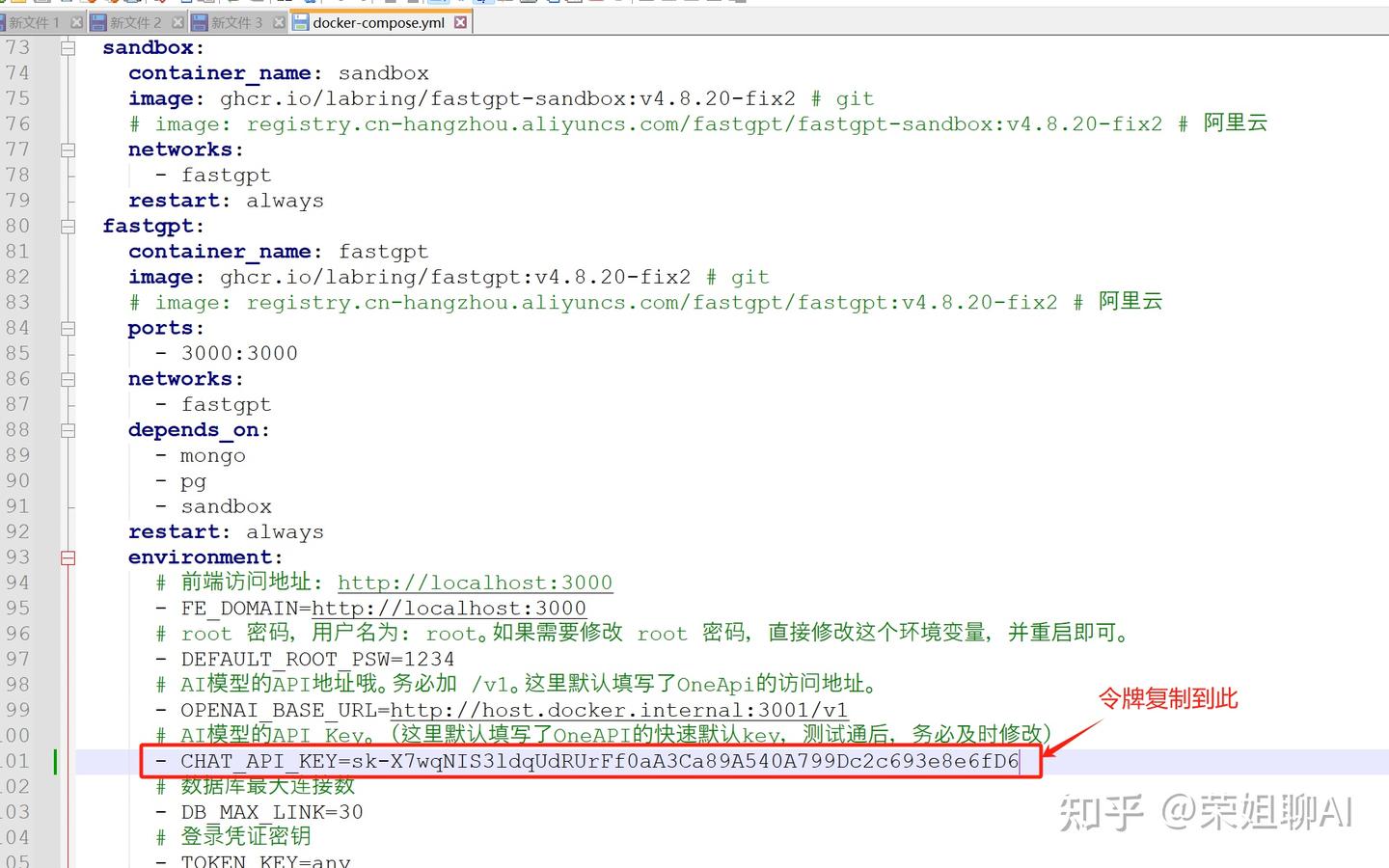
3.2.4 修改配置文件
修改docker-compose.yml配置文件,把刚才的令牌添加的 CHAT_API_KEY 配置中。
3.3 配置FastGPT
3.3.1 登录fastGPT
在 docker 中点击 fastgpt ,打开fastgptgpt页面。
默认账号密码为:root/1234
登录后界面如下:
3.3.2 配置模型
点击账号,选择模型提供商,点击模型配置,点击右上角新增模型。
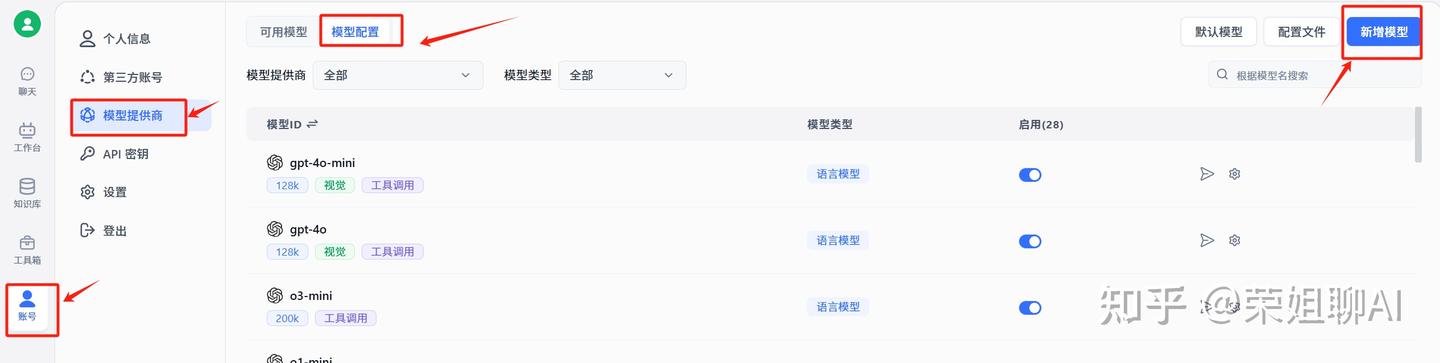
1、新增语言模型deepseek
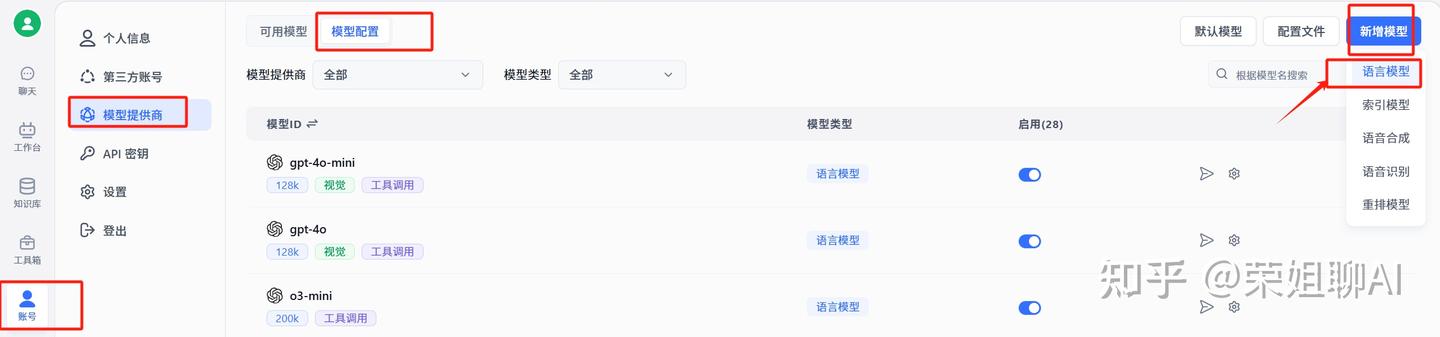
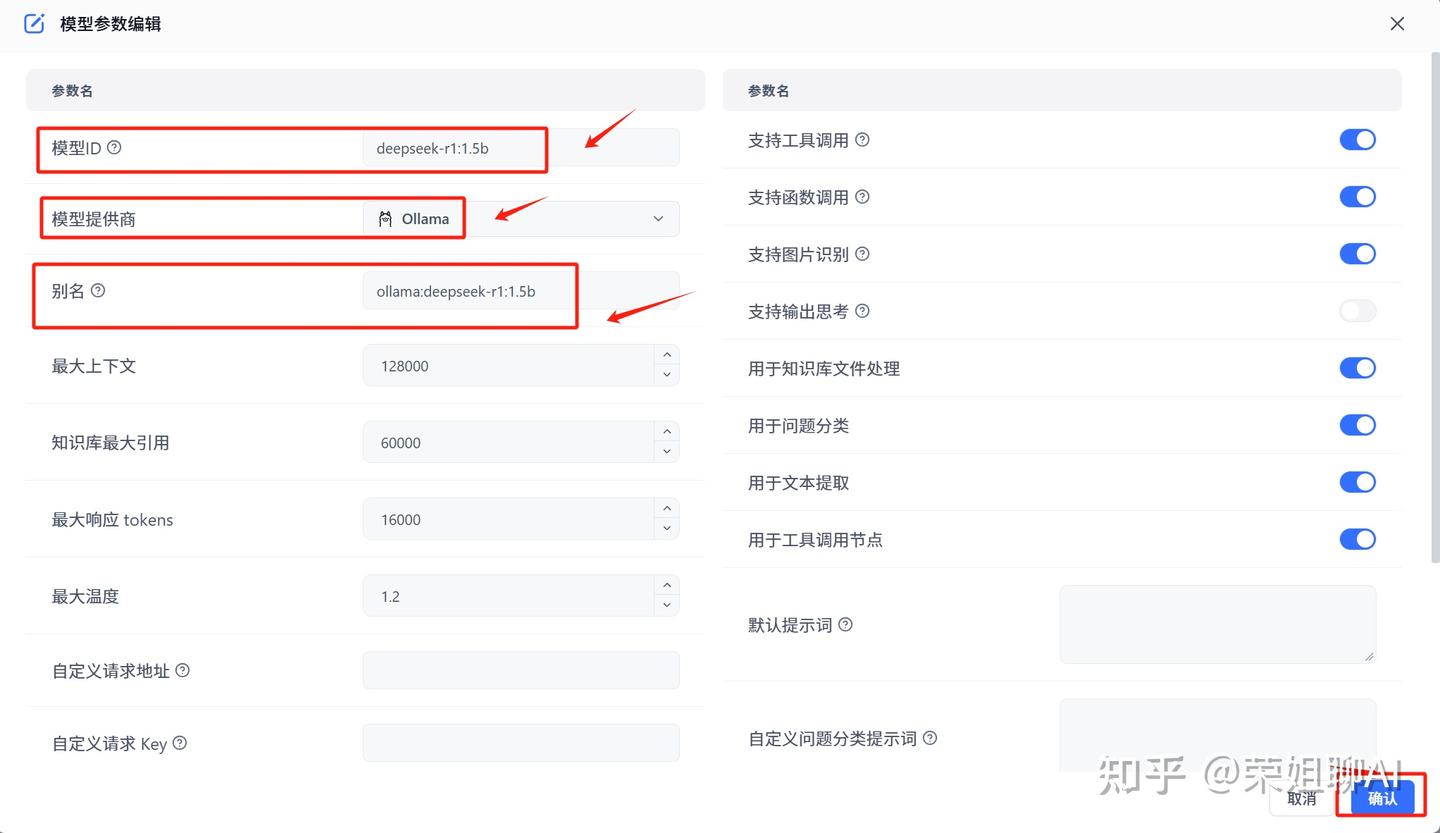
填写模型ID,模型提供商,别名。
模型 ID 与 OneAPI 那里要一致。
2、新增索引模型
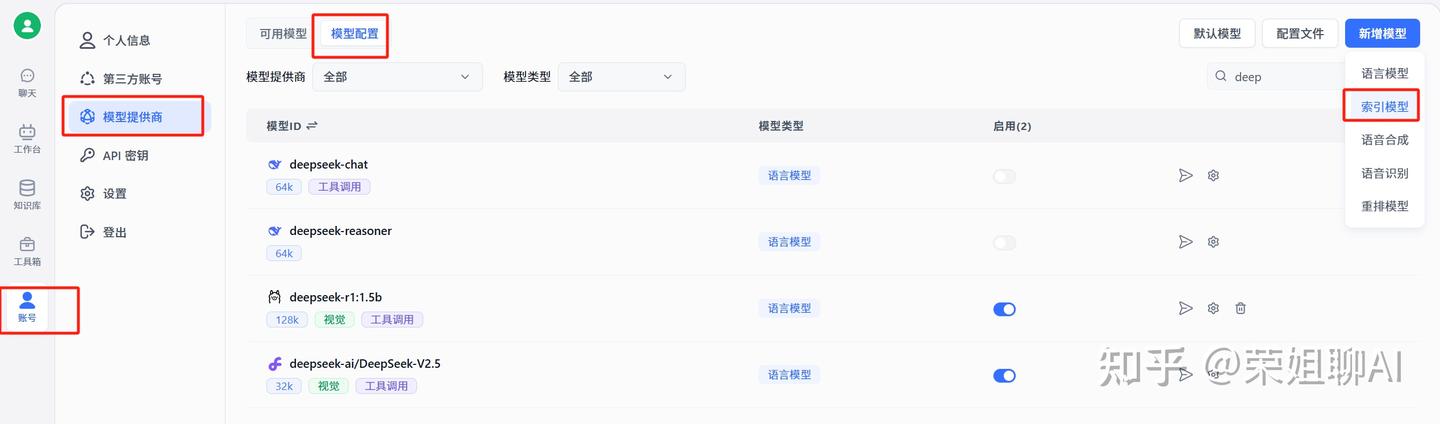
填写模型ID,选择模型提供商为Ollama,填写别名。
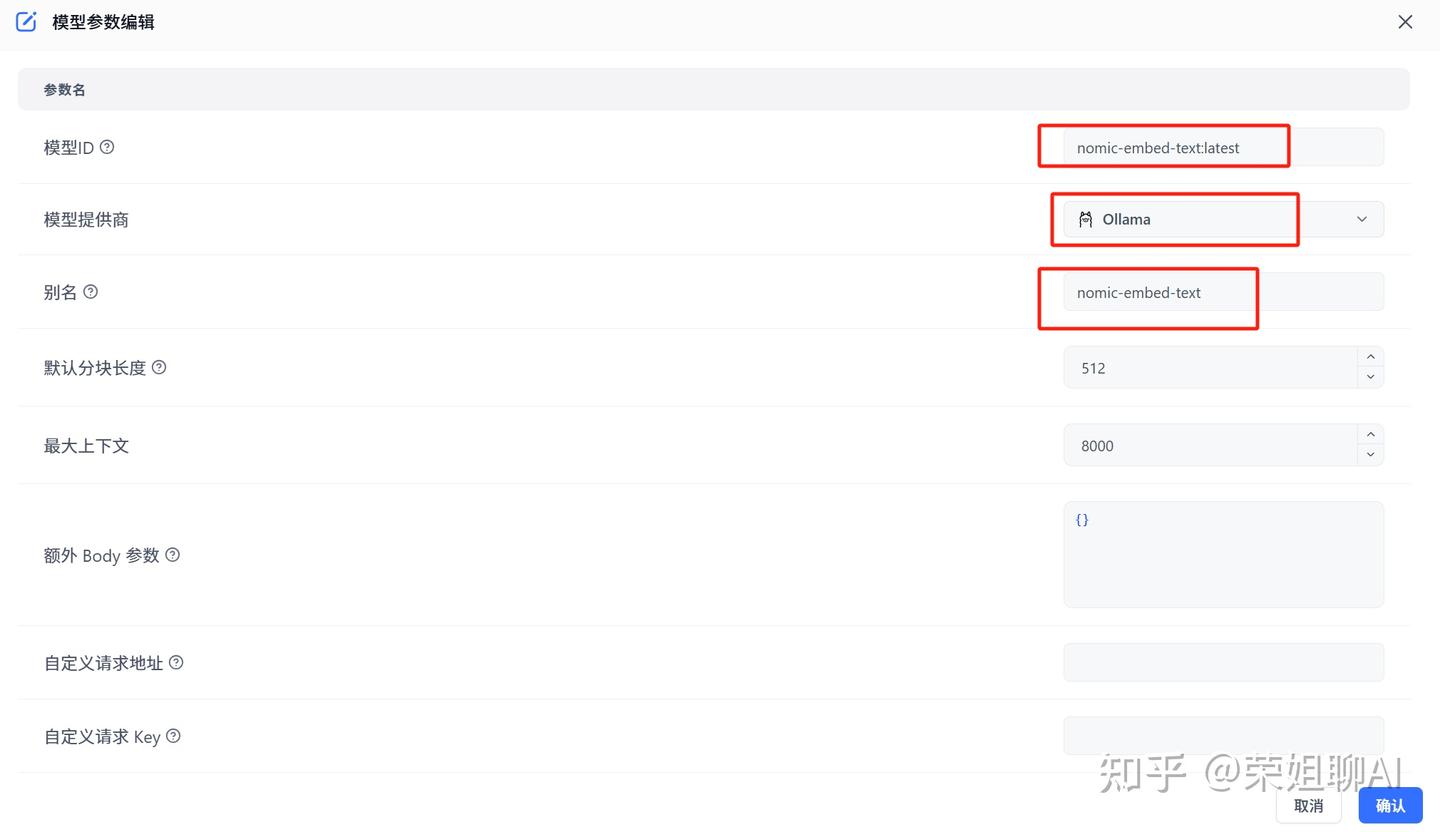
3.3.3 测试模型
模型添加好后,点击测试按钮进行测试。

显示成功就证明可以了。
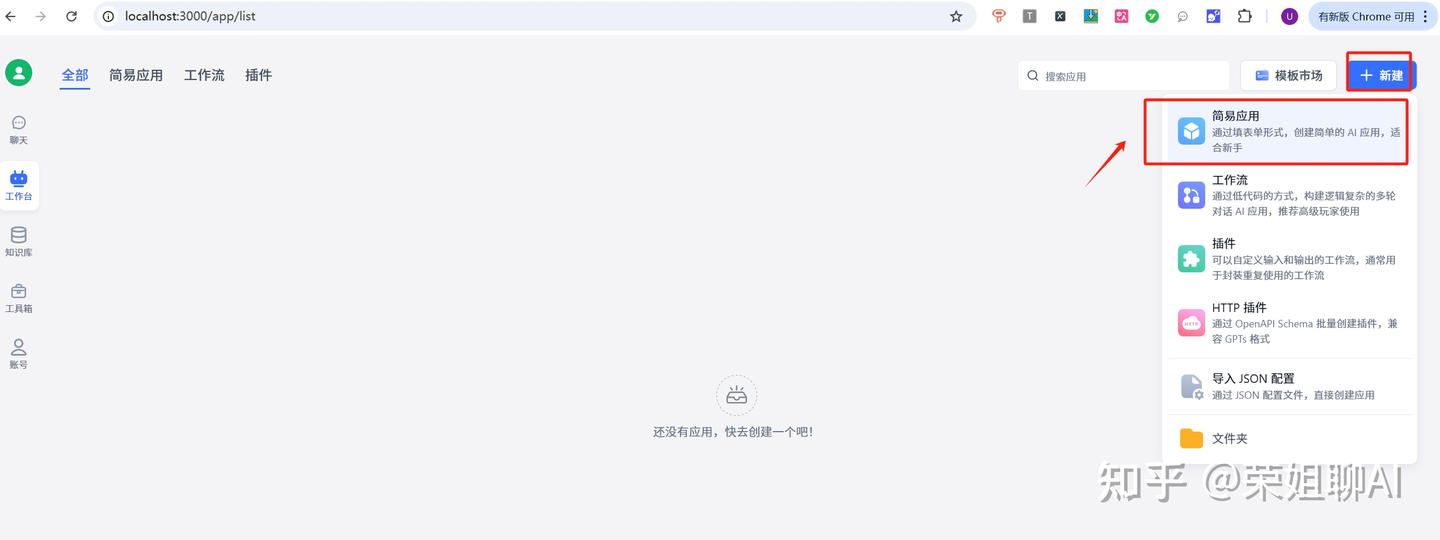
3.4 创建应用
1、在工作台中创建简易应用。
2、输入应用名称,我这里随便起了test。创建空白应用。
3、AI模型选择Ollama->deepseep
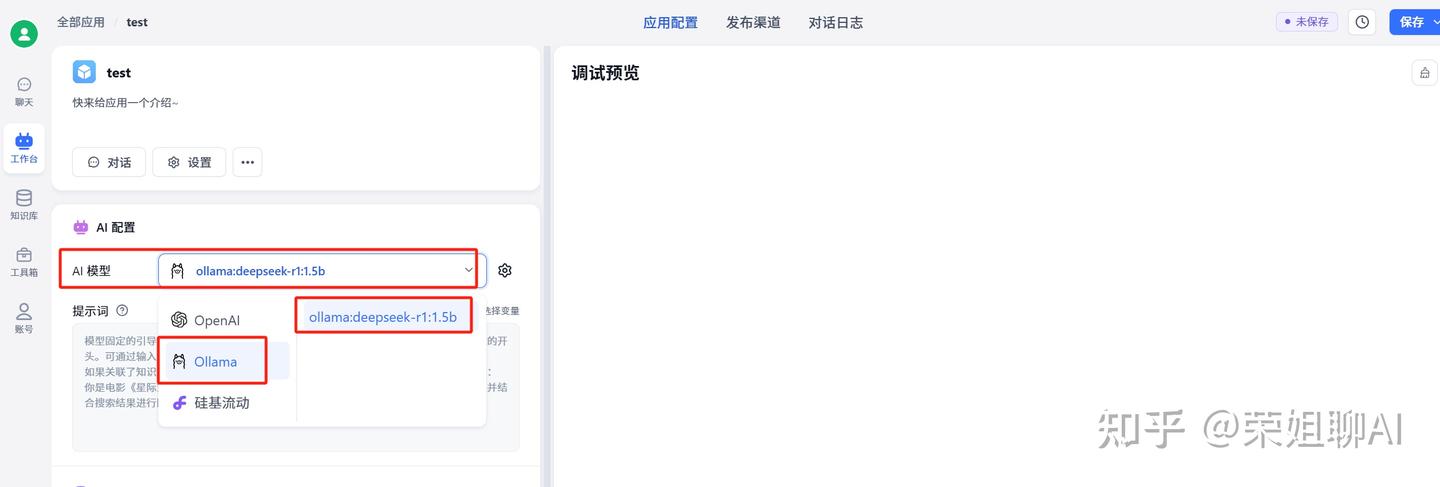
4、在右侧聊天区域进行测试,输入你是谁测试一下,可以看到已经返回答案了。
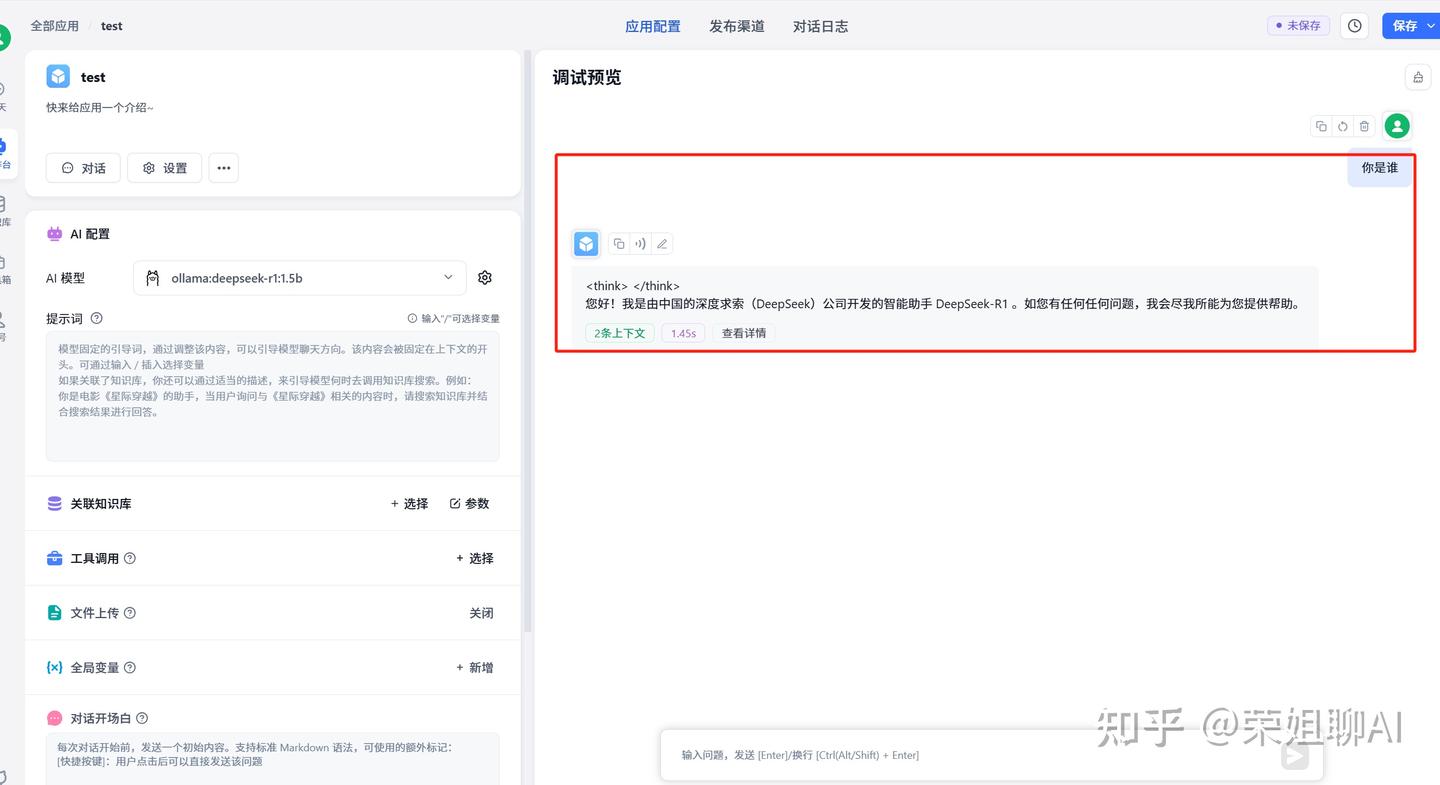
3.5 添加本地知识库
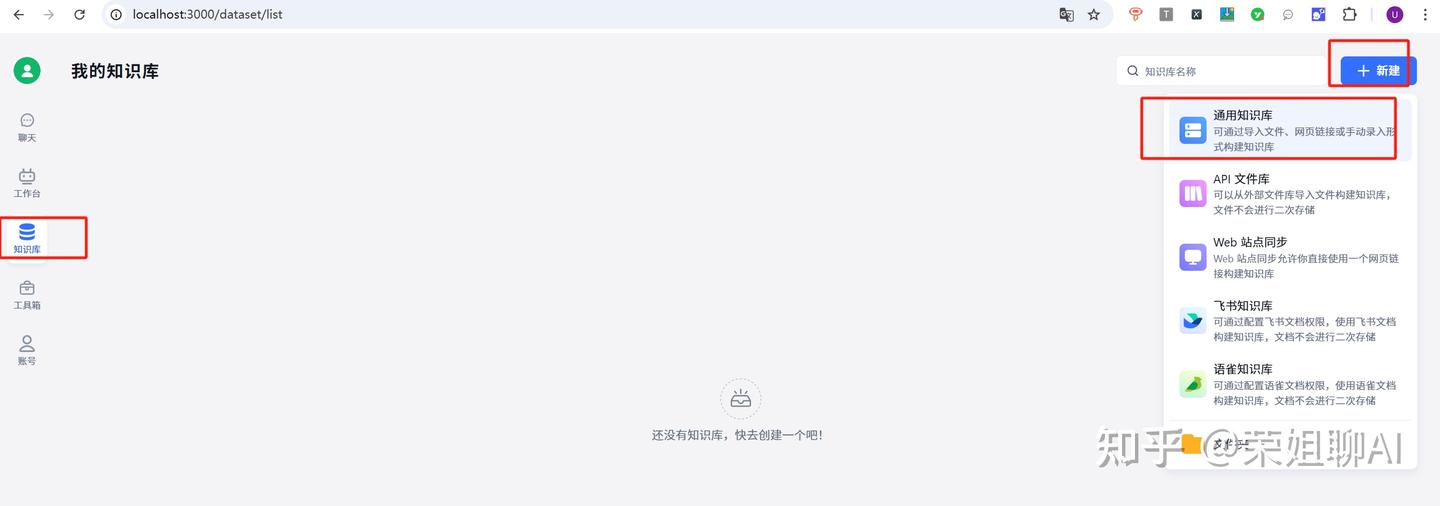
1、新建知识库
选择左侧菜单栏中知识库,点击右上角新建,荣姐今天拿本地文档测试,选择通用知识库。
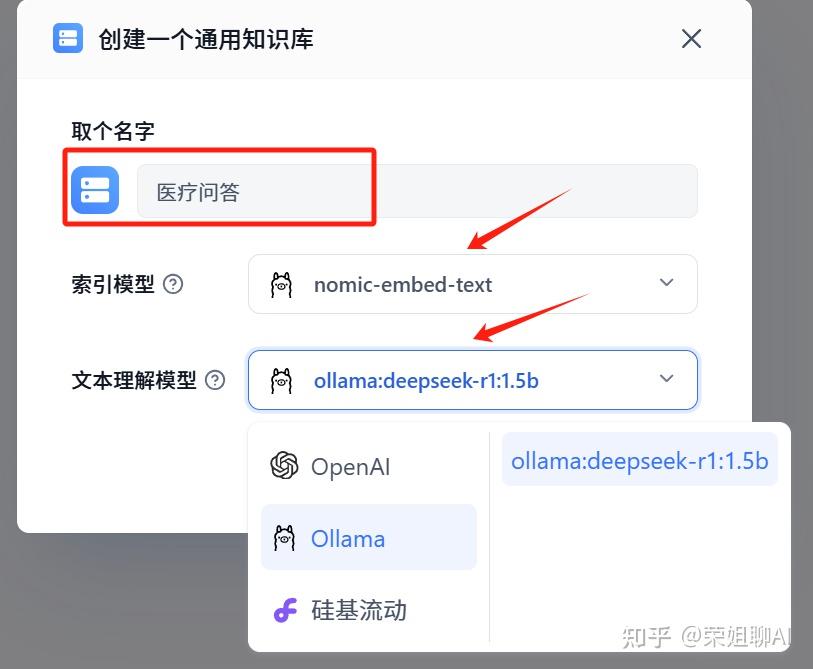
2、填写知识库名称,选择索引模型和文本理解模型,都是选择Ollama下面的,索引和文本就是我们之前配置的。
点击确认创建。
3、新建一个文本数据集
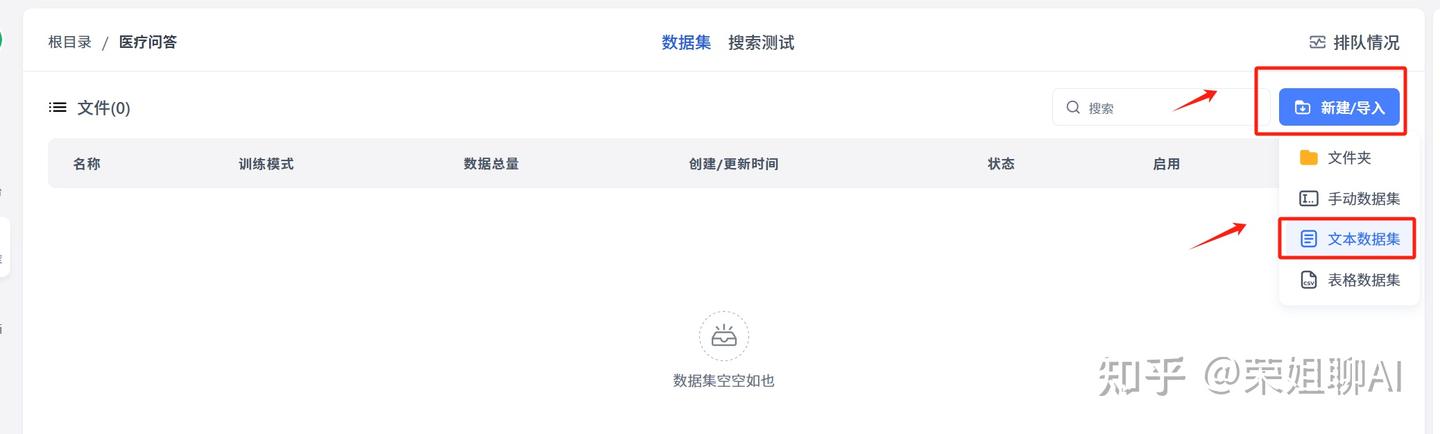
4、来源就选本地文件了。点击确定。
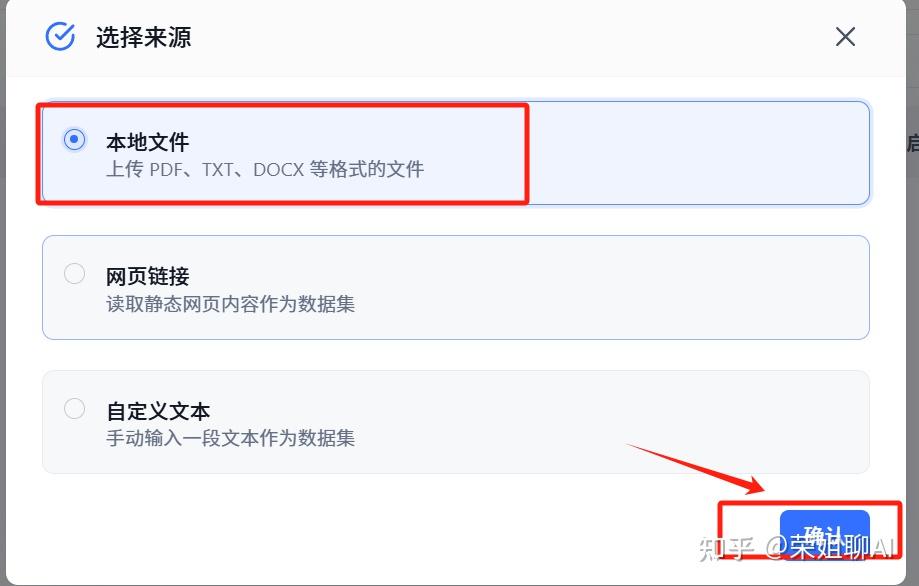
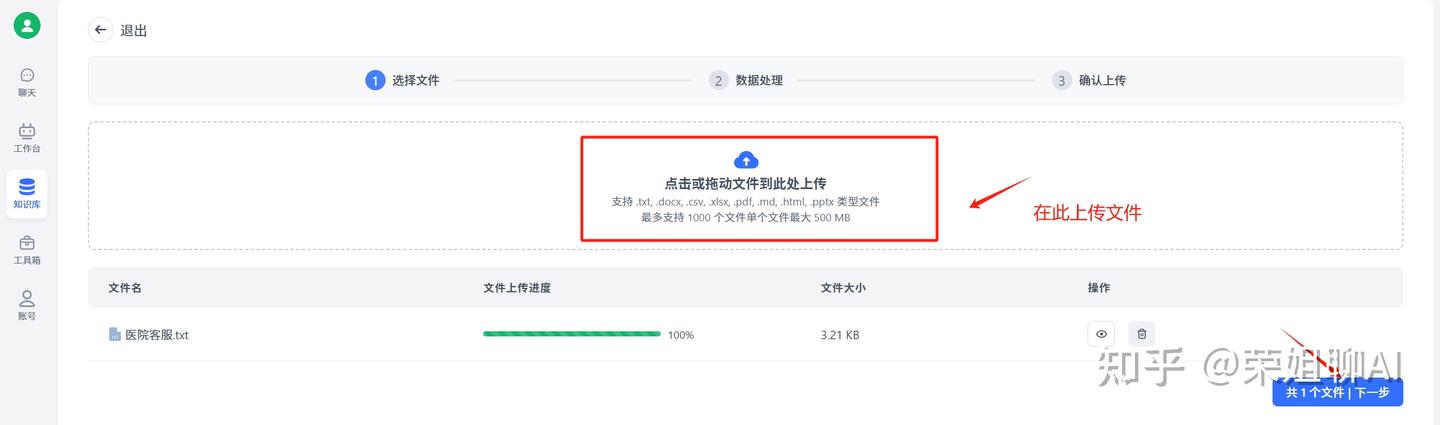
5、上传本地文件,点击下一步
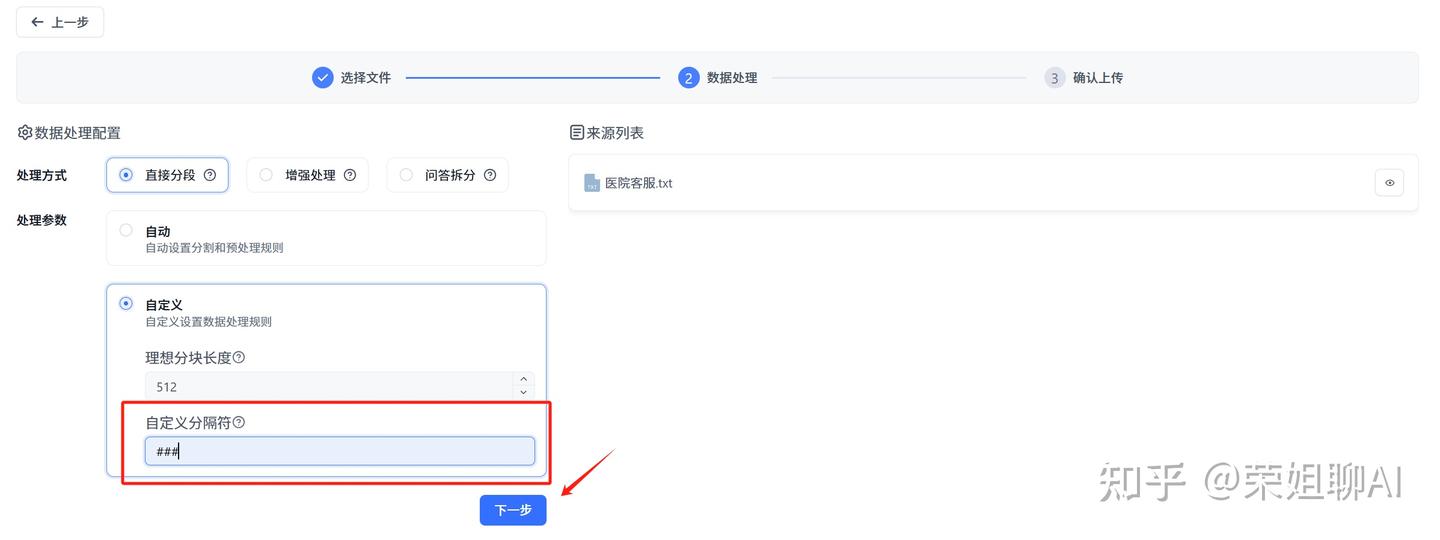
6、数据处理,可以默认分段,也可以选择自定义分隔符。点击下一步。
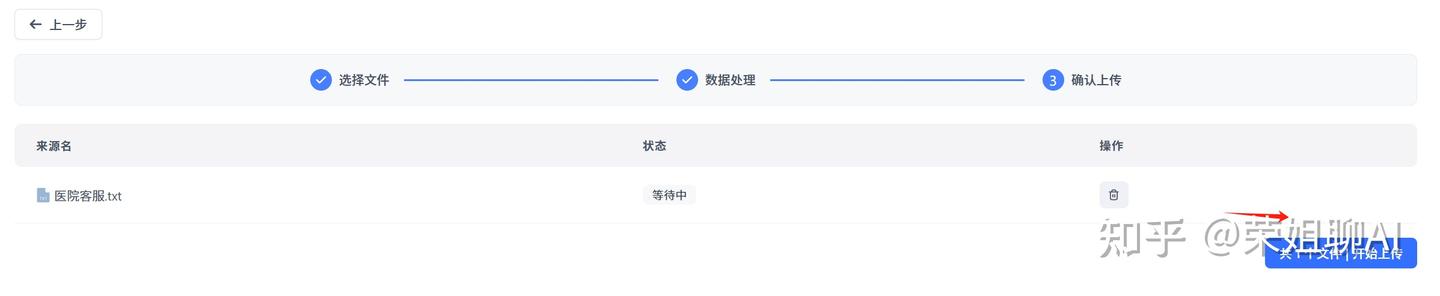
7、点击开始上传。
8、看到已就绪,证明已搭建好知识库了。
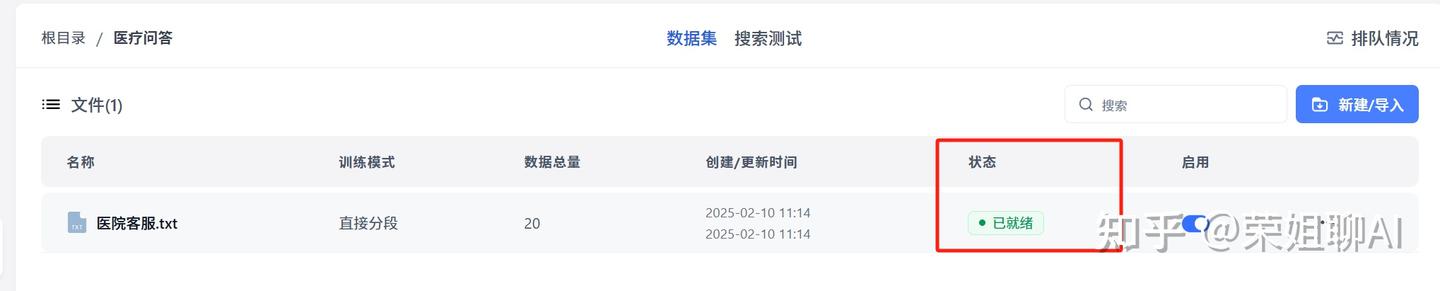
9、查看知识库
可以点击进去查看,就是做好分段的一个个问答对了。
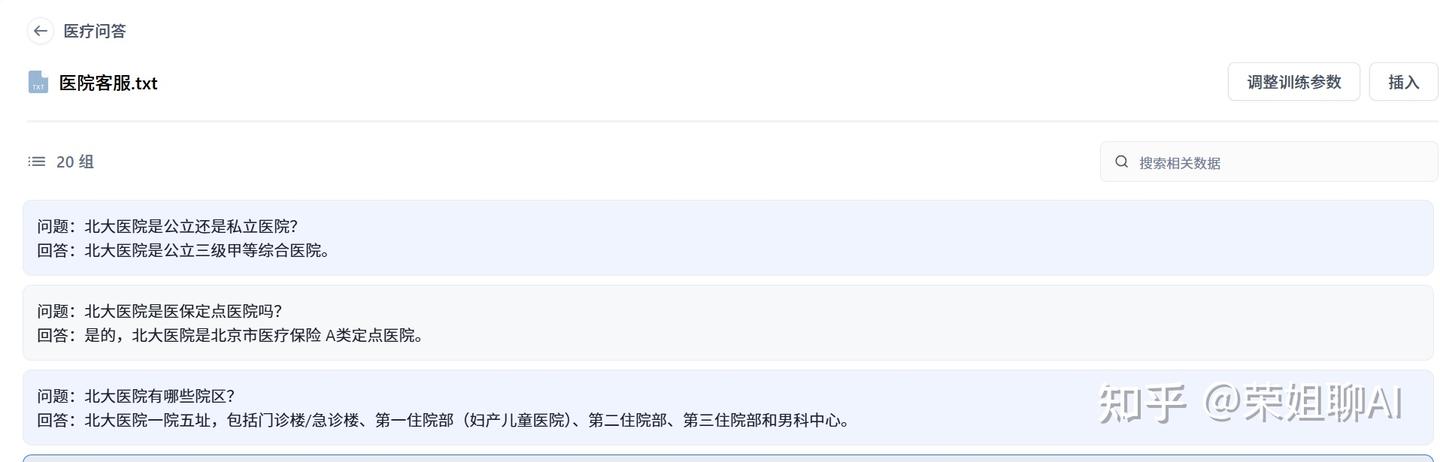
3.6 测试知识库
知识库搭建好后,我们在应用中引用这个知识库。
在工作台中打开之前创建好的那个test应用。
在关联知识库那里点击选择。
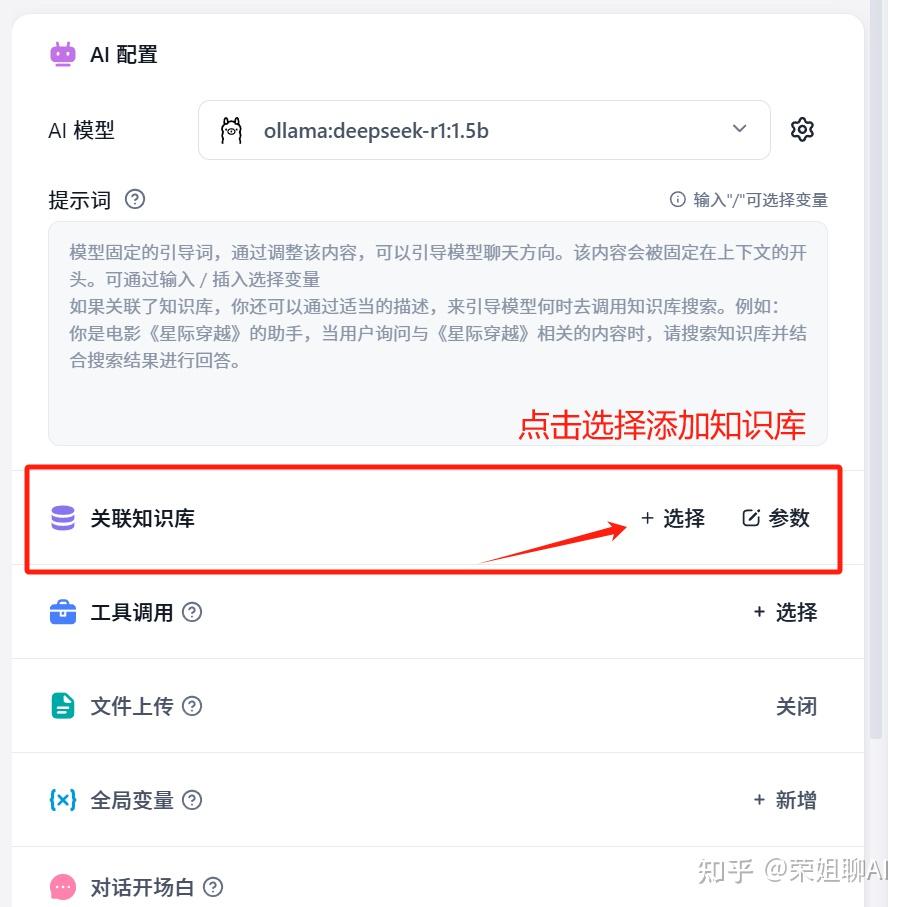
选择之前创建的医疗问答知识库。点击完成。
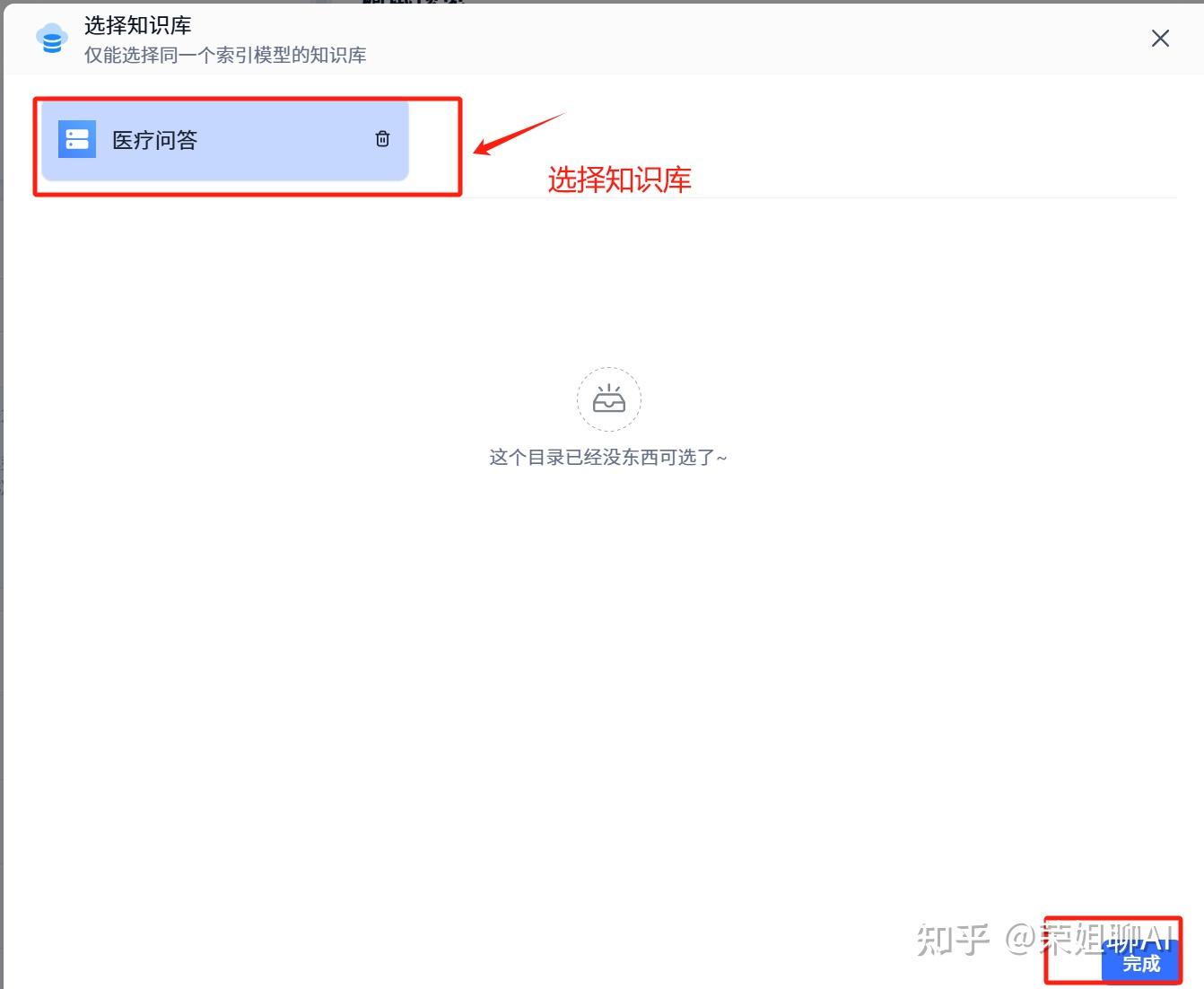
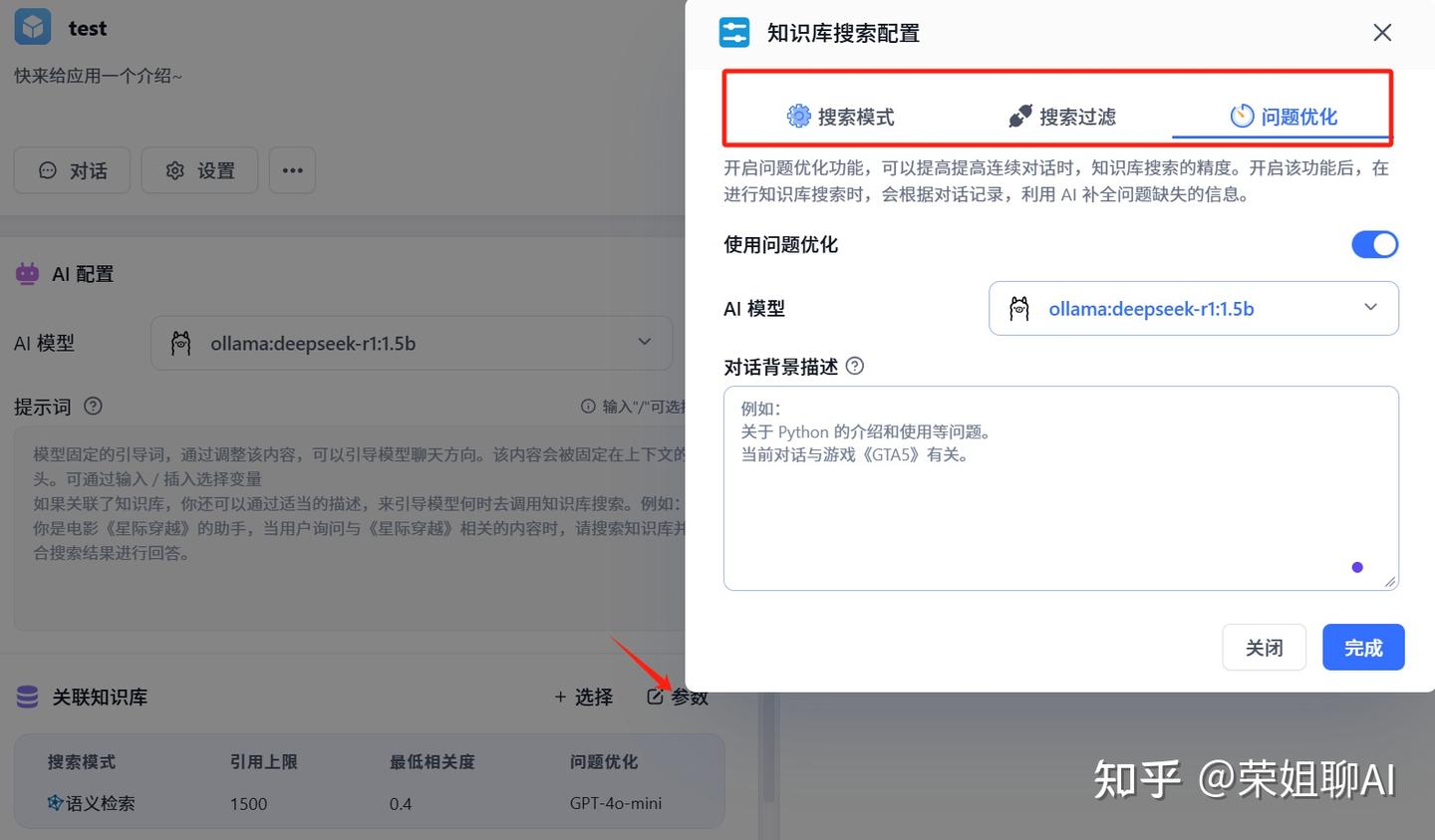
点击参数进行配置,可以设置搜索模式、搜索过滤和问题优化,AI模型还是选择deepseek r1。
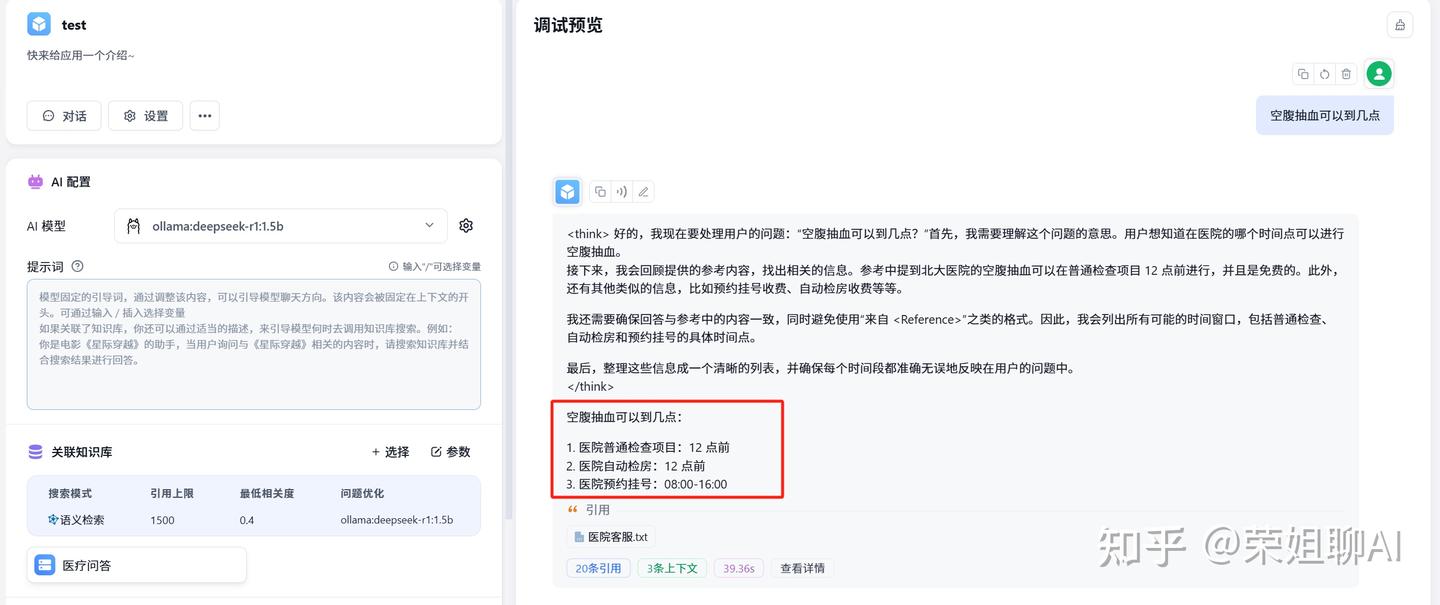
测试一下。我输入了个问题:空腹抽血可以到几点?
可以看到给出了思考过程,并且显示了引用的知识库文档,处理时间及详情信息。
看到这里,你是否觉得构建智能应用并非遥不可及?技术赋能的时代已经来临,关键在于勇敢地拥抱它。
要知道,当工具变得触手可及,真正能决定你成就的,唯有你的创意与实践。
大家可以动起手来,搭建个本地知识库后,还可以顺便定制属于自己的工作流,更加助力企业与个人。

