
参考资料主教程地址:https://zhuanlan.zhihu.com/p/704991238
参考资料辅助教程地址:https://zhuanlan.zhihu.com/p/22819951868 (写的不太清楚,丢了很多步骤)
一、安装docker,windows版或linux版,参照教程即可。【本地用的docker桌面版+Ubuntu20.04.6 LTS,但服务器可选择linux版】
二、安装ollama同时确保正常运行。
步骤:
安装ollama:docker pull ollama/ollama:latest
运行ollama:docker run -d --name ollama -p 11434:11434 ollama/ollama:latest
在浏览器中访问 http://localhost:11434,你应该能看到 Ollama 的 Web UI,或者你可以使用 curl 来测试 API:curl http://localhost:11434/api/models
停止或重启ollama:docker stop ollama docker start ollama
三、如果使用模型的话需要下载对应的模型(参照步骤四run命令),例如:这里使用chat模型wen2:7b + 索引模型nomic-embed-text:latest,那么需要执行如下命令进行拉取安装启动模型:
ollama run qwen2:7b && ollama run nomic-embed-text:latest 【在步骤六配置渠道后,点击“渠道测试”前一定要通过Ollama安装启动好这两个模型,否则OneAPI渠道测试会提示:“http://host.docker.internal:11434/api/chat 接口404”】
四、安装fastgpt,参照教程启动容器即可。【安装时修改docker-compose.yml,注意:OPENAI_BASE_URL和下面一样,要修改为host.docker.internal,不能使用127.0.0.1或localhost,否则都无法访问到,在fastgpt控制台进行模型测试也会“Connection error.”。亦或者给docker配置网卡内网Ip也行】
五、进入OneAPI配置渠道和令牌,参照教程:
本地OneAPI控制台账号密码:root / Hll334136
先配置语言模型渠道:【Chat 模型(对话模型)正常返回response——支持OneAPI渠道测试】
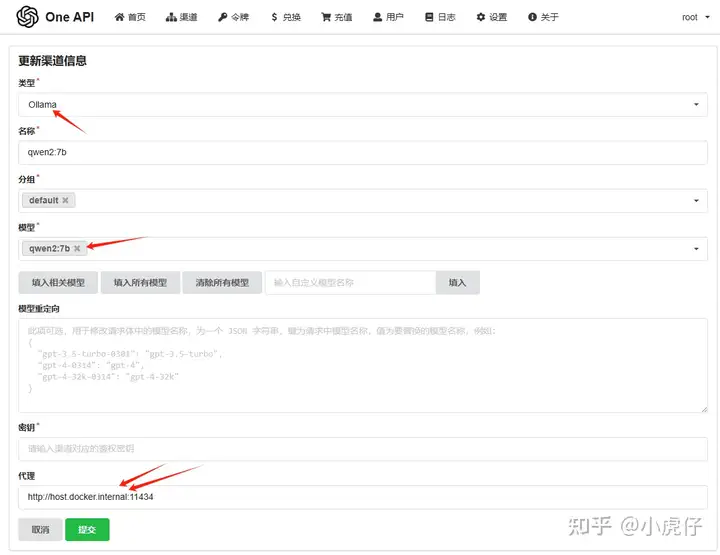
类型选择:Ollama
名称:尽量和使用的模型名称保持一致
模型:这里在下方输入qwen2:7b,并填入
代理:这里需要填写host.docker.internal + 11434端口号【默认只能填host.docker.internal,不能使用127.0.0.1或localhost,否则都无法访问到,会提示“dial tcp [::1]:11434: connect: connection refused”。亦或者给docker配置网卡内网Ip也行】
保存后进行渠道测试即可。
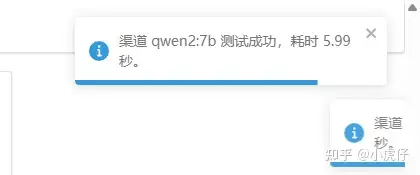
再配置知识库索引模型渠道:【索引模型(Embedding 模型)不会返回response——也不支持OneAPI渠道测试】
类型选择:Ollama
名称:尽量和使用的模型名称保持一致
模型:这里在下方输入ollama:nomic-embed-text,并填入
代理:这里需要填写host.docker.internal + 11434端口号【默认只能填host.docker.internal,不能使用127.0.0.1或localhost,否则都无法访问到,会提示“dial tcp [::1]:11434: connect: connection refused”。亦或者给docker配置网卡内网Ip也行】
配置正确保存成功即可,不支持渠道测试。【真要测可以到FastGPT控制台-模型管理中进行“模型测试”,如下成功即可】

六、配置FastGPT,用于创建模型、应用、知识库(步骤七),整体参照教程即可。
参照教程创建模型(不过我这里选择的不是deepseek而是qwen2:7b,原理一样)
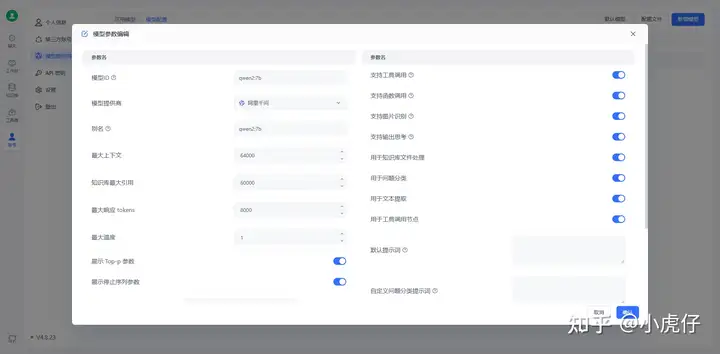
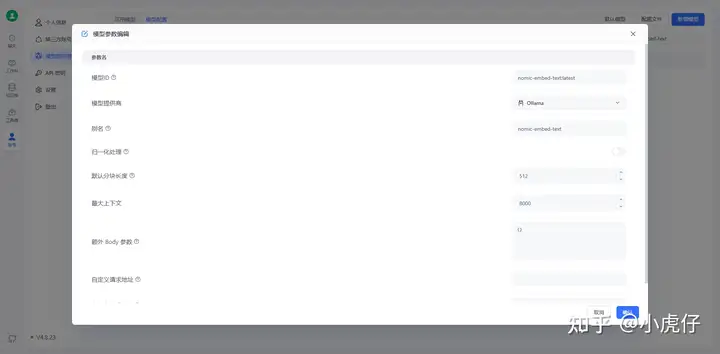
创建完成并渠道测试成功即可。
再到工作台中创建简易空白应用:
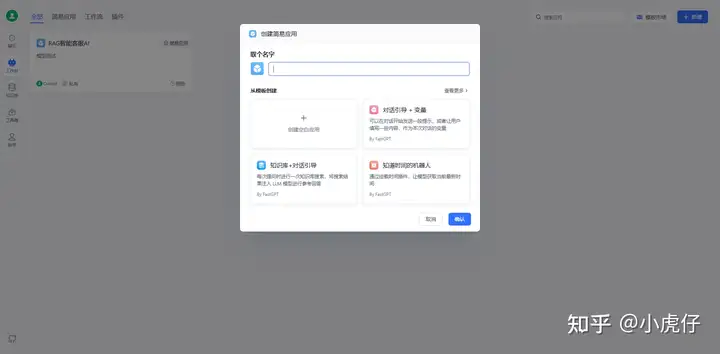
选择AI模型(Chat模型)和知识库嵌入模型(Embedding模型):其他设置自己摸索一下即可
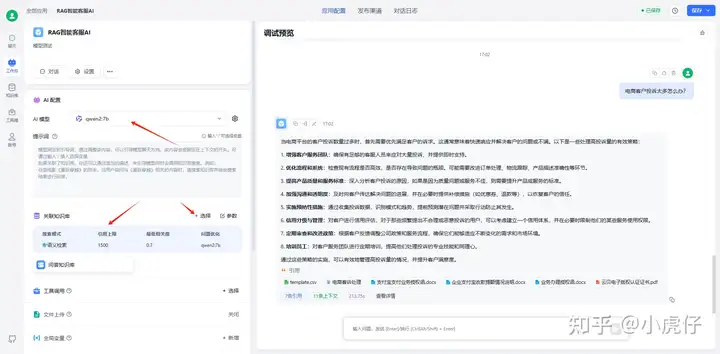
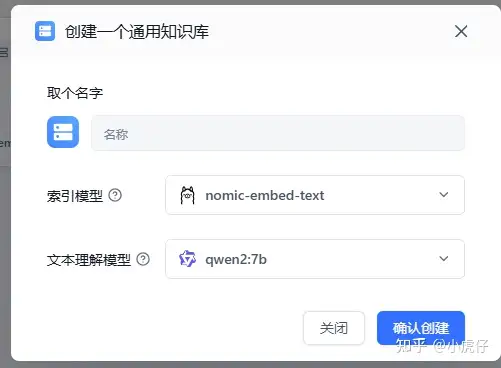
七、添加知识库:
在fastGPT知识库中创建通用知识库,模型在该示例中选择如截图:
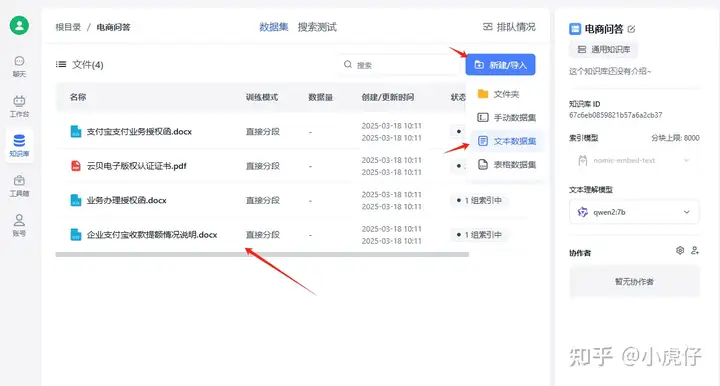
创建后导入部分文档到知识库中:
前面的主教程中有提到下载运行模型:ollama pull nomic-embed-text。
如果前面忘了执行,那么在fastGPT中创建索引模型后,模型测试会报错“code:500”,在docker控制台查看容器fastgpt日志提示:“404 Api response error: /api/core/ai/model/test?model=nomic-embed-text:latest”,需补执行:ollama run nomic-embed-text:latest,此时如果没拉取的话,会自动pulling模型。
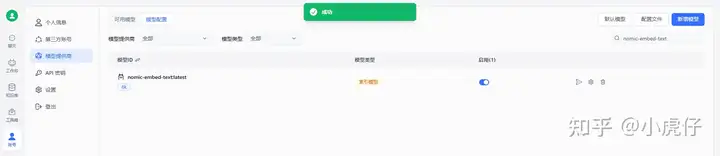
启动后再测试就OK了。
八、无需训练的模型部署就完成了,下面测试一下:
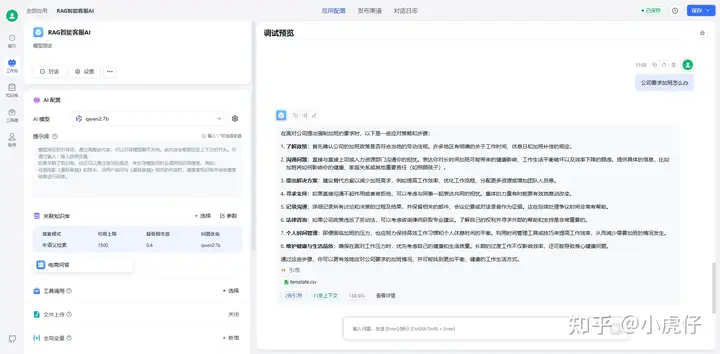
这就OK了。
九、如果需要通过接口API调用的话,在“发布渠道-API访问”新建API密钥,并copy保存。
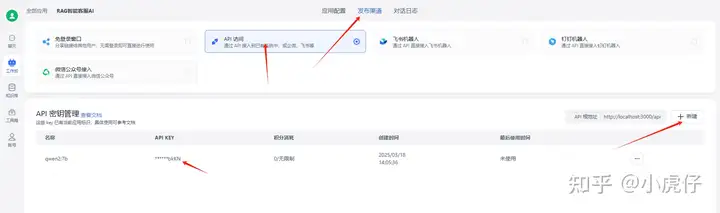
具体接口调用传参,可以点击“查看文档”查看出入参:
这里以我使用postman调用为例:
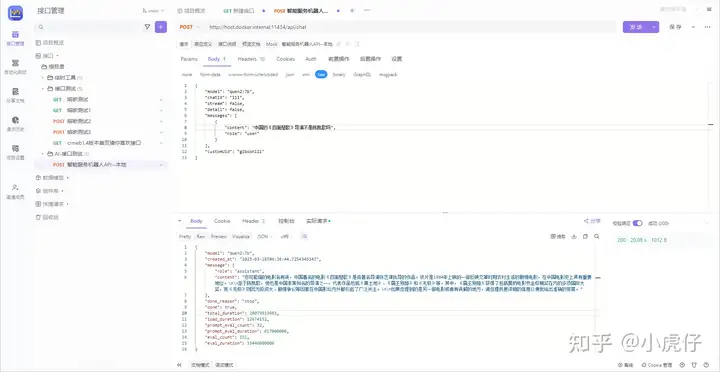
接口名:http://host.docker.internal:11434/api/chat
入参:
{
"model": "qwen2:7b",
"chatId": "111",
"stream": false,
"detail": false,
"messages": [
{
"content": "中国的《四面楚歌》导演不是陈凯歌吗",
"role": "user"
}
],
"customUid": "gibson111"
}
返回结果:
{
"model": "qwen2:7b",
"created_at": "2025-03-18T06:38:44.725434514Z",
"message": {
"role": "assistant",
"content": "您可能指的电影名有误,中国著名的电影《四面楚歌》是由著名导演张艺谋执导的作品。该片是1984年上映的一部反映文革时期农村生活的剧情电影,在中国电影史上具有重要地位。\n\n至于陈凯歌,他也是中国非常知名的导演之一,代表作品包括《黄土地》、《霸王别姬》和《无极》等。其中,《霸王别姬》获得了包括戛纳电影节金棕榈奖在内的多项国际大奖,而《无极》则因为投资大、剧情争议等因素在中国影坛内外都引起了广泛关注。\n\n如果您提到的是另一部电影或者有误解的地方,请您提供更详细的信息以便我给出准确的答案。"
},
"done_reason": "stop",
"done": true,
"total_duration": 20079519981,
"load_duration": 12674152,
"prompt_eval_count": 32,
"prompt_eval_duration": 617000000,
"eval_count": 151,
"eval_duration": 19446000000
}
至此就告一段落了。接下来几天研究一下通过LoRA对deepseek或qwen大模型进行微调的部分,结束了上教程和测试效果。
注:这里再补充一个坑吧。【没遇到可以直接忽略】
问题:一开始问答时,发现回答引用的文件少了,始终只引用一个固定文件。
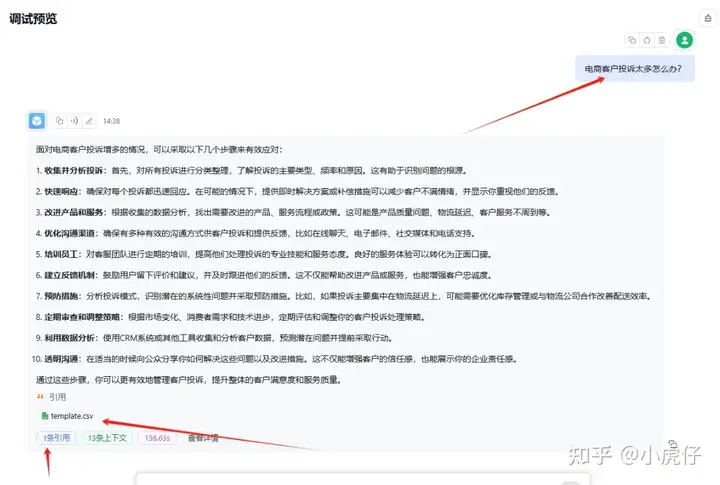
最后社区问了,发现是因为:知识库中文档解析出来的数据量都是 - 导致的,没有解析成功。
解决方案:
重新点击进入重新一个一个保存上传一次就好了,可能是上午手动批量上传导致没有解析成功。

